|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
Задачи повышенной сложности: ExamExt25, ExamExt53Группы ExamExt и ExamFExt содержат задания, аналогичные тем которые предлагались на ЕГЭ по информатике в качестве задач повышенной сложности. Начальную часть данной группы составляют задания на обработку сложных наборов данных (записей) с элементами-полями различных типов. В подобных заданиях требуется правильно выбрать способ хранения данных и организовать их эффективную обработку; при этом обычно требуется применить несколько базовых алгоритмов, например, алгоритм суммирования или нахождения минимума/максимума и алгоритм поиска нужного элемента или сортировки набора данных по требуемому ключу. Следует заметить, что возможность автоматической генерации больших наборов исходных данных, предоставляемая задачником Programming Taskbook, позволяет существенно ускорить тестирование учебных программ и сделать его более надежным. В заданиях групп ExamExt и ExamFExt ввод и вывод имеет те же особенности, что и в заданиях групп ExamBase и ExamFBase. Подобно группам ExamBase и ExamFBase, группы ExamExt и ExamFExt отличаются только способом ввода исходных данных (в заданиях группы ExamFExt исходные данные требуется читать их текстового файла). Рассмотрим следующее задание. ExamExt25°. На вход подаются сведения об абитуриентах. В первой строке
указывается количество абитуриентов N, каждая из последующих N строк имеет
формат Программа-заготовка, созданная для этого задания, подобно заготовкам для заданий группы ExamBase, будет использовать специальный модуль PT4Exam: {$mode delphi}{$H+}
program ExamExt25;
uses PT4Exam;
// Для ввода используйте процедуру Read или Readln
// Для вывода используйте процедуру Write или Writeln
// Между полученными результатами надо выводить символ пробела
begin
Task('ExamExt25');
end.
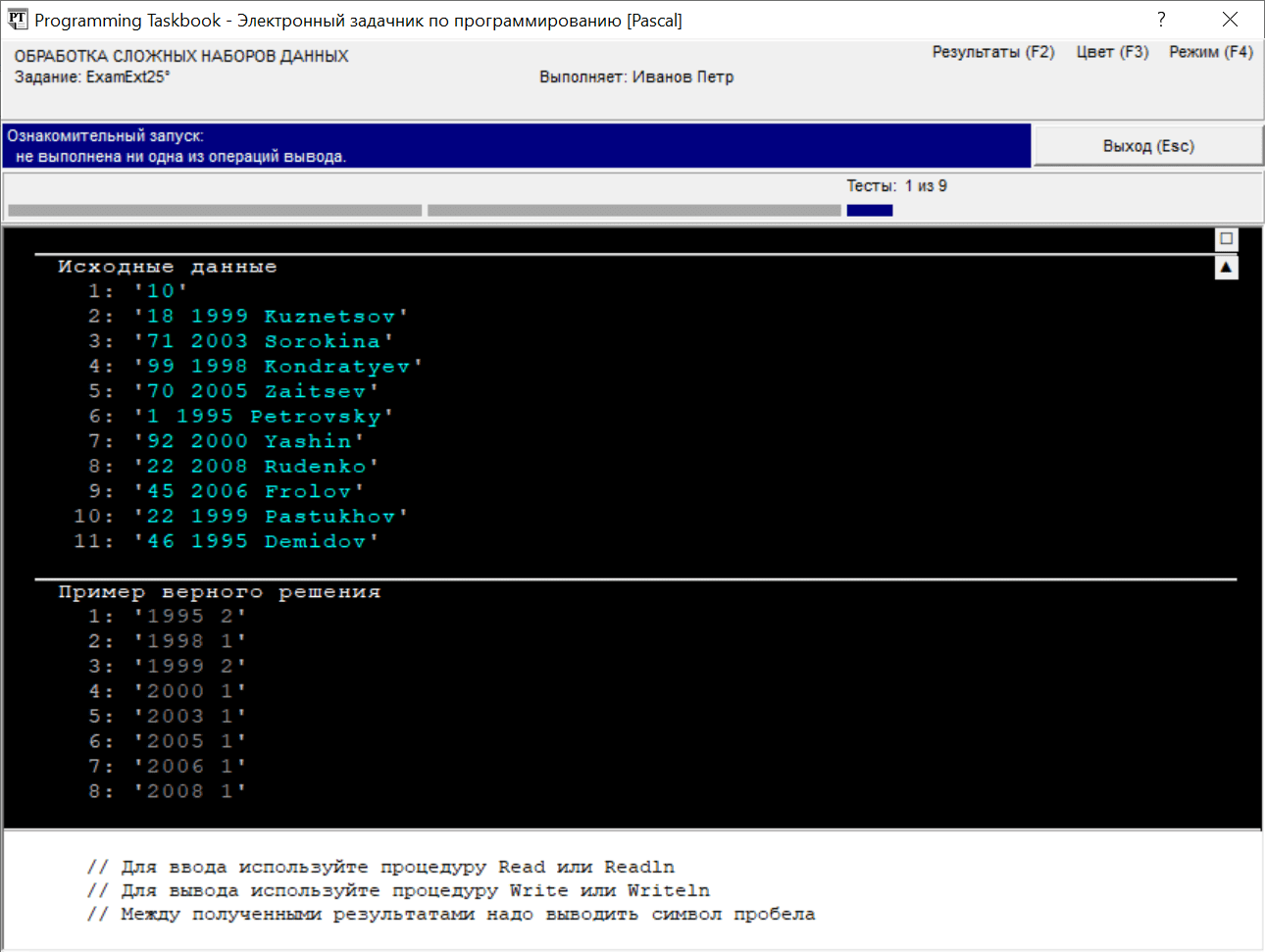
При запуске этой программы на экране появится окно задачника, содержащее следующие данные:
Окно будет иметь такой вид, если при его предшествующем закрытии оно находилось в режиме отображения всех данных. Для отображения всех данных на экране может потребоваться увеличить высоту окна; для этого достаточно зацепить мышью заголовок окна и переместить его вверх (для перемещения заголовка окна задачника вверх и вниз можно также воспользоваться клавиатурными комбинациями [Ctrl]+{Up] и [Ctrl]+[Down]). При первом тестовом испытании программы ей будет предложен для обработки набор данных не слишком большого размера (порядка 10–20 элементов). Вначале следует определиться со структурами данных, которые будут использоваться в программе. Поскольку требуется найти одну характеристику для каждого года, а число лет невелико, можно использовать числовой массив year, каждый элемент которого соответствует определенному году. Так как в языке Pascal можно использовать произвольные границы индексов, удобно в качестве диапазона индексов указать диапазон лет, который требуется проанализировать: 1990..2010. В начале программы выполним инициализацию элементов массива, положив их значения равными 0 (заметим, что если после обработки исходных данных некоторые элементы массива year останутся нулевыми, то это будет означать, что соответствующие годы не были представлены в наборе исходных данных, и выводить информацию о них не следует). После инициализации массива следует прочесть информацию о количестве абитуриентов и организовать цикл, в котором будут обрабатываться данные о каждом абитуриенте и соответствующим образом корректироваться элементы массива year. В дальнейшем сведения об уже обработанном абитуриенте нам не будут нужны, поэтому сохранять их в специальном наборе данных (например, массиве) не требуется. Заметим также, что фамилия абитуриента для решения задачи не требуется, поэтому после чтения двух числовых данных можно сразу переходить к новой строке, пропуская строковый элемент данных (фамилию). В задаче не нужно использовать и номера школ, однако их придется считывать, так как только после номера школы указывается интересующий нас год поступления абитуриента. Когда данные обо всех абитуриентах будут обработаны, в массиве year будет содержаться вся необходимая информация, которую останется вывести в формате, указанном в условии задачи. Приведем первый вариант решения (этот вариант содержит одну ошибку): {$mode delphi}{$H+}
program ExamExt25;
uses PT4Exam;
// Для ввода используйте процедуру Read или Readln
// Для вывода используйте процедуру Write или Writeln
// Между полученными результатами надо выводить символ пробела
var
n, i, k, m: integer;
year: array[1990..2010] of integer;
begin
Task('ExamExt25');
for i := 1990 to 2010 do
year[i] := 0;
Readln(n);
for i := 1 to n do
begin
Readln(k, m); // k - номер школы, m - год поступления
Inc(year[m]);
end;
for i := 1990 to 2010 do
Writeln(i, ' ', year[i]);
end.
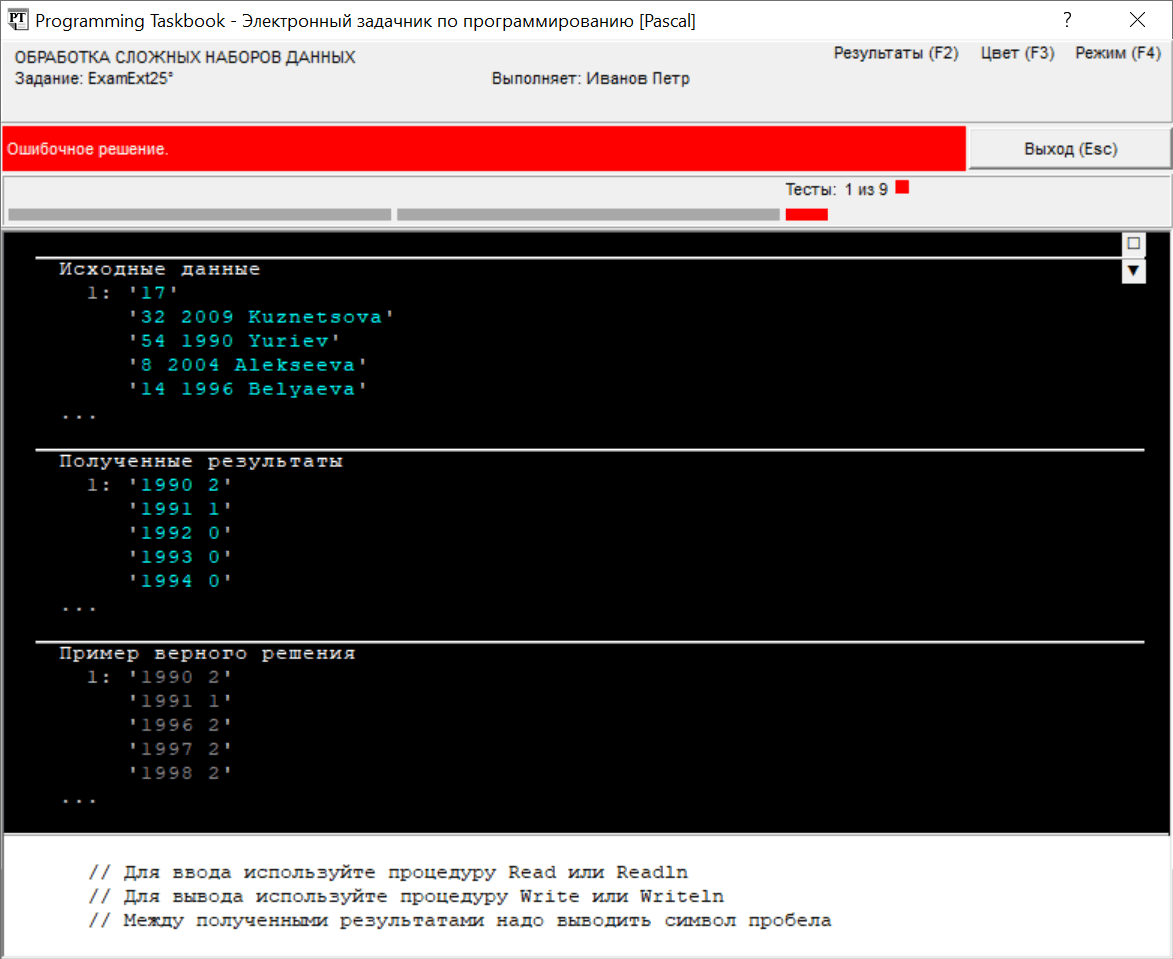
Ошибка связана с тем, что на экран выводится информация о годах, отсутствующих в наборе исходных данных. Поэтому она сразу будет выявлена при обработке наборов данных небольшого размера, предлагаемых программе при первом тестовом запуске (для большей наглядности приведем окно задачника в режиме сокращенного отображения данных, при котором выводятся только пять первых элементов из каждого набора данных):
Обратите внимание на многоточия, указанные в нижней части разделов с исходными данными, полученными результатами и примером правильного решения. Эти многоточия показывают, что во всех разделах отображается только часть связанных с ними данных. Для исправления ошибки достаточно добавить в последний цикл условный оператор: for i := 1990 to 2010 do
if year[i] > 0 then
Writeln(i, ' ', year[i]);
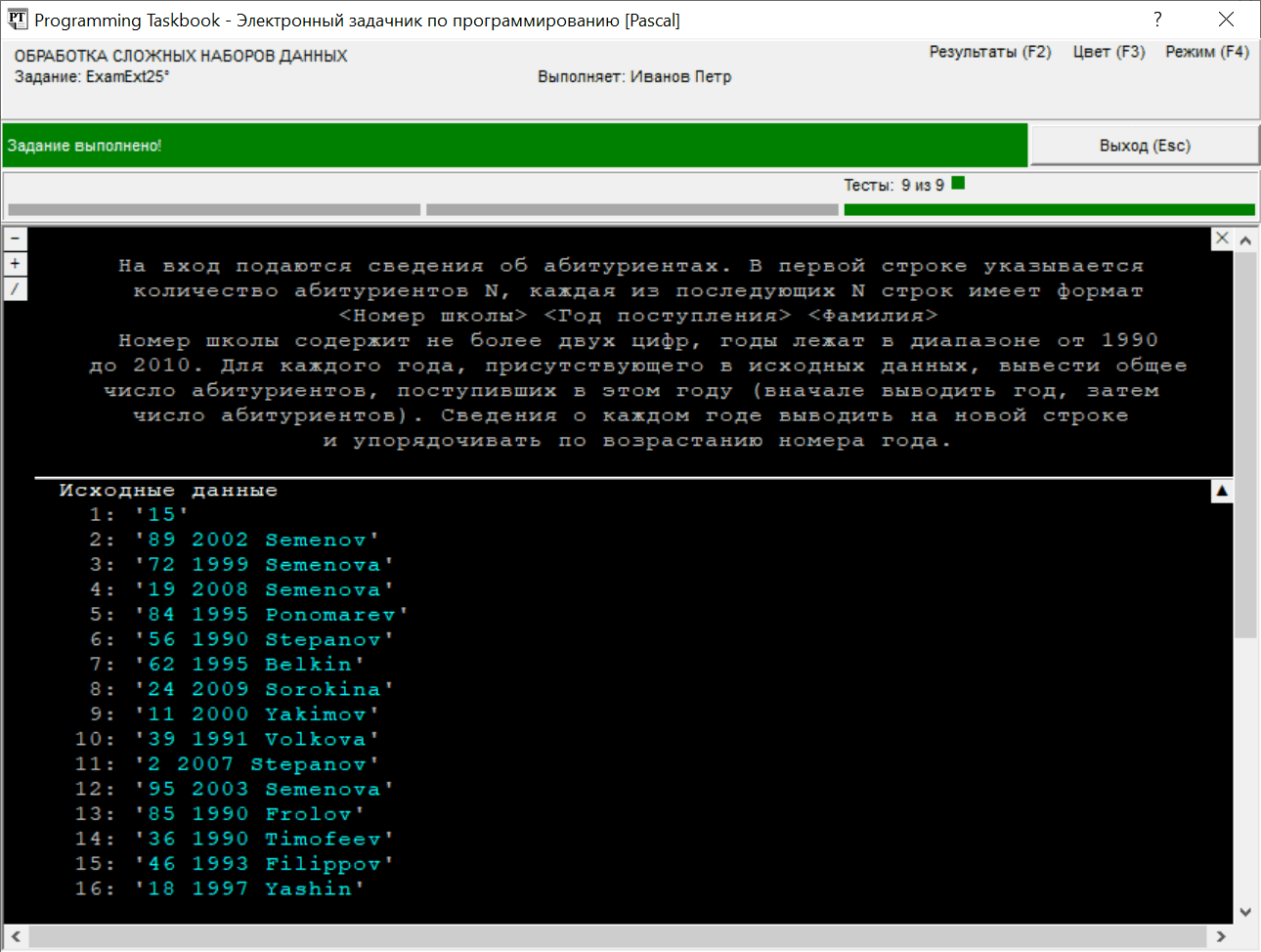
Теперь все 9 тестовых испытаний программы, требуемых для того, чтобы решение было зачтено как выполненное, будут пройдены успешно. Завершая рассмотрение этого задания, опишем некоторые дополнительные возможности, связанные с просмотром больших наборов данных. Начиная со второго испытания, программе может быть предложен для обработки набор исходных данных большего размера (порядка 50–100 элементов). При этом уже не удастся отобразить на экране все данные, связанные с заданием. В подобной ситуации у правой границы окна задачника появится полоса прокрутки, позволяющая перемещаться к той части данных, которая первоначально не отображается на экране. Прокрутку данных можно выполнять не только с помощью полосы прокрутки, но и используя клавиши со стрелками, [PgUp], [PgDn], [Home], [End], а также колесико мыши. Помимо стандартных действий по прокрутке данных, в окне задачника предусмотрены возможности «интеллектуальной» прокрутки, позволяющие быстро перейти к началу каждого раздела задания, а также сравнить соответствующие фрагменты полученных результатов и примера верного решения. Для циклического перебора разделов сверху вниз предназначена клавиша [+] (а также комбинация [Ctrl]+[PgDn]), для циклического перебора разделов снизу вверх — клавиша [–] (а также комбинация [Ctrl]+[PgUp]). Для быстрого переключения между соответствующими фрагментами разделов с результатами и с примером верного решения предназначена клавиша [/] (а также комбинация [Ctrl]+[Tab]). Все эти действия можно выполнить и с помощью мыши; для этого предусмотрены кнопки в левом верхнем углу прокручиваемой области окна, отведенной под отображение разделов задания (эти кнопки отображаются на экране, если размер данных, связанных с заданием, превышает размеры окна). Приведем вид окна задачника с полосой прокрутки и дополнительными кнопками:
Обозначения на кнопках совпадают с клавишами, выполняющими те же действия; при наведении мышью на кнопку рядом с ней появляется всплывающая подсказка. Кроме трех кнопок, связанных с «интеллектуальной» прокруткой, в приведенном на рисунке окне отображаются еще две дополнительные кнопки. Первая из них располагается в правом верхнем углу раздела с формулировкой и позволяет временно скрыть (а в дальнейшем опять отобразить) раздел с формулировкой (эти же действия можно выполнить с помощью клавиши [Del] или двойного щелчка мышью на разделе с формулировкой). Вторая дополнительная кнопка расположена в правом верхнем углу раздела с исходными данными. Как уже отмечалось ранее, эта кнопка позволяет переключаться между полным и сокращенным отображением наборов данных. Напомним, что изображение на этой кнопке показывает текущий режим отображения данных. Например, если на кнопке изображена стилизованная стрелка, направленная вверх (как на приведенном выше рисунке), значит, в данный момент в окне отображаются все данные, а нажатие на эту кнопку переведет окно в режим отображения нескольких начальных (как правило, пяти) элементов каждого набора данных. Решение с файловым вводом исходных данныхПриведем решение, в котором используется ввод данных из текстового файла (соответствующая задача имеет имя ExamFExt25). {$mode delphi}{$H+}
program ExamFExt25;
uses PT4ExamTasks;
// Исходные данные следует вводить с помощью процедур файлового ввода
// Для вывода используйте процедуру Write или Writeln
// Между полученными результатами надо выводить символ пробела
var
filename: string;
f : text;
n, i, k, m: integer;
year: array[1990..2010] of integer;
begin
Task('ExamFExt25');
filename := GetString; // имя исходного файла
for i := 1990 to 2010 do
year[i] := 0;
Assign(f,filename);
Reset(f);
Readln(f, n);
for i := 1 to n do
begin
Readln(f, k, m); // k - номер школы, m - год поступления
Inc(year[m]);
end;
Close(f);
for i := 1990 to 2010 do
if year[i] > 0 then
Writeln(i, ' ', year[i]);
end.
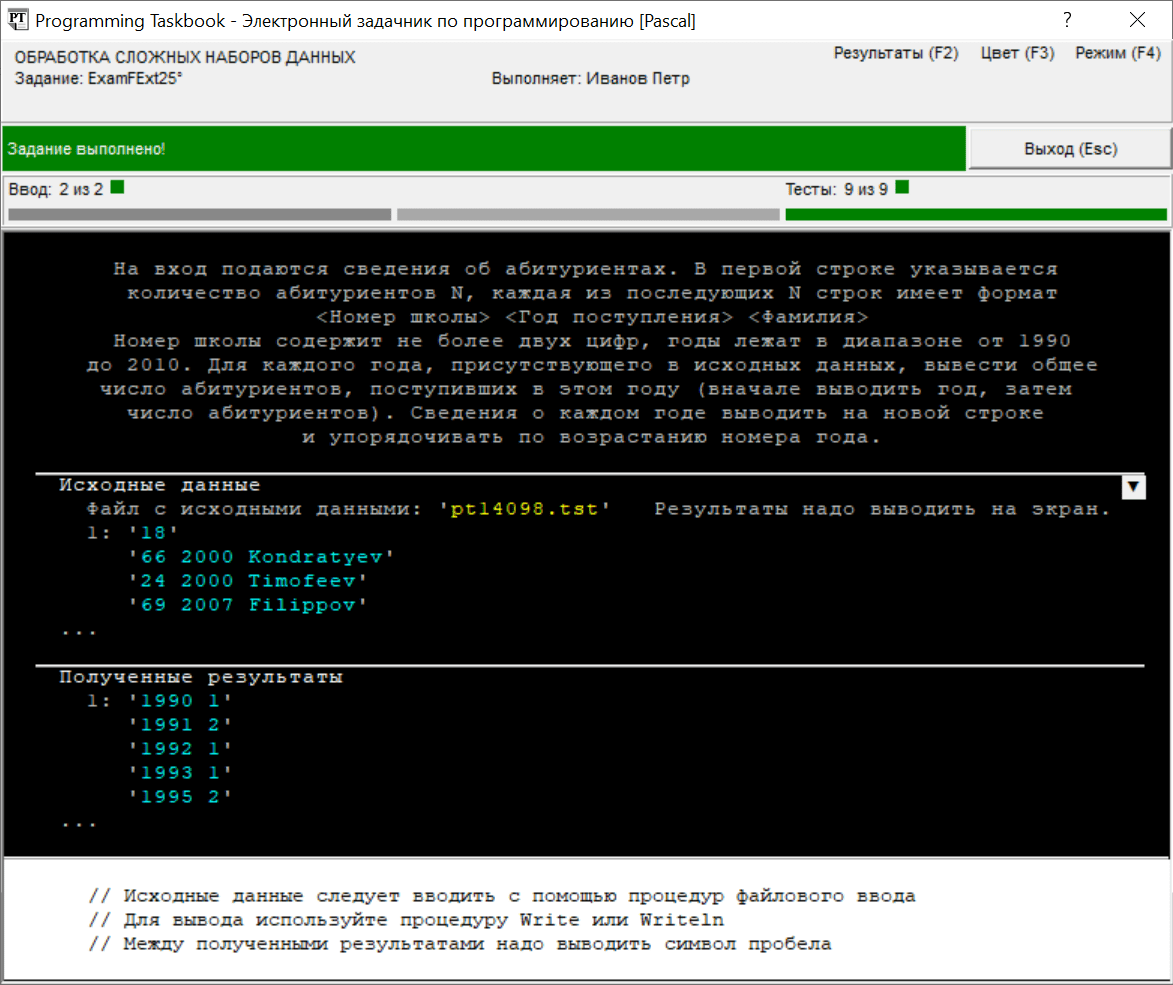
После проверки программы на девяти наборах тестовых данных будет выведено сообщение о том, что задание выполнено:
Теперь рассмотрим более сложное задание. ExamExt53°. На вход подаются сведения о ценах на бензин на автозаправочных станциях (АЗС).
В первой строке содержится значение M одной из марок бензина, во второй строке указывается
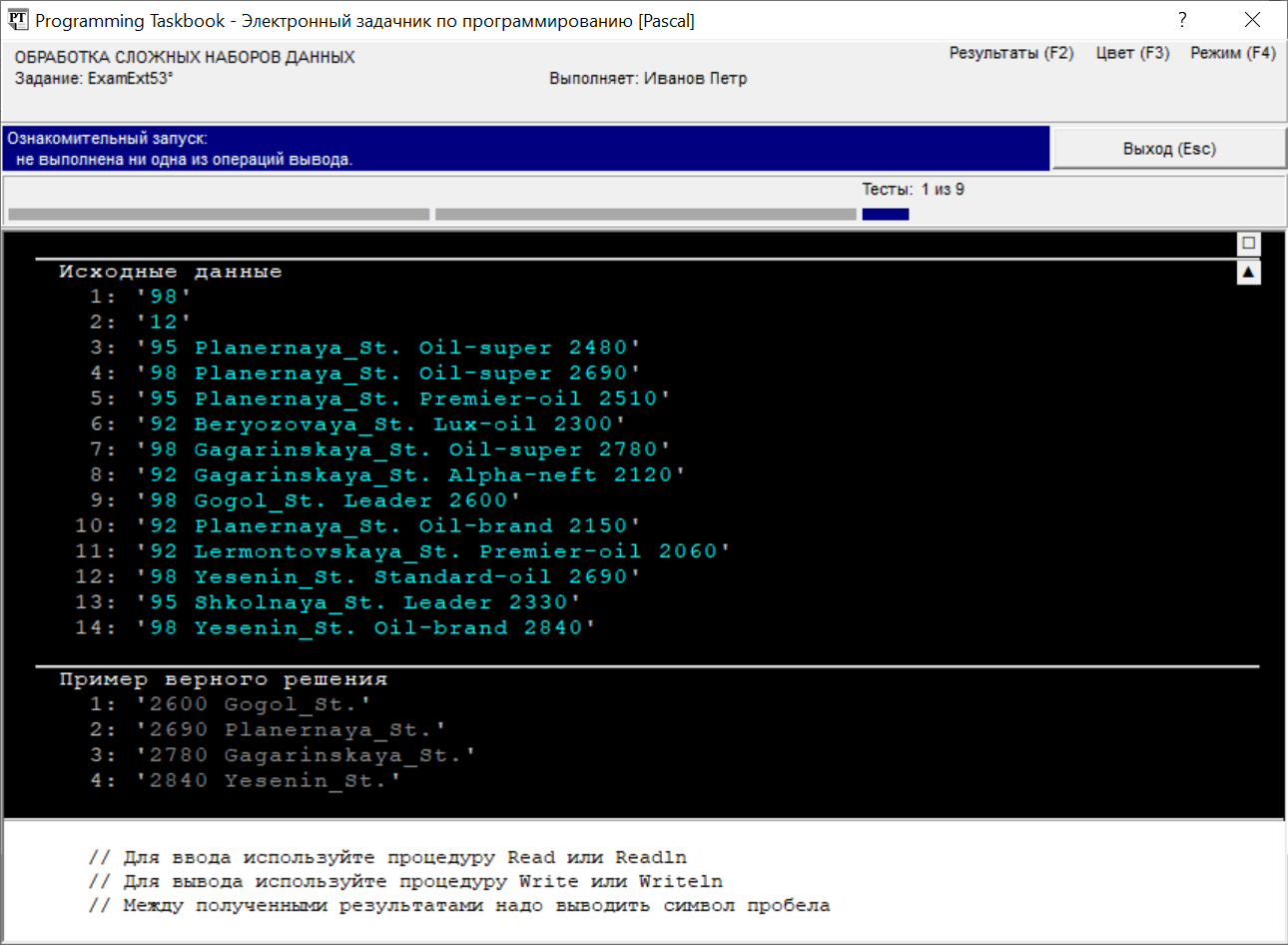
целое число N, а каждая из последующих N строк имеет формат Приведем окно задачника, которое появится на экране при запуске программы-заготовки для данного задания (в данном окне скрыт раздел с формулировкой; в результате оказались скрытыми и кнопки, отвечающие за «интеллектуальную» прокрутку, поскольку в окне полностью отображается содержимое оставшихся разделов):
Выясним, какая структура является наиболее подходящей для хранения информации, необходимой для решения задачи. Нам требуется информация, связанная с различными улицами, которых по условию не более 30, причем для каждой улицы надо хранить сведения двух видов: ее название и максимальную цену бензина марки M. Поэтому мы можем либо завести массив из 30 элементов-записей с двумя полями, либо два массива: один содержащий названия улиц, а другой — максимальные цены. Учитывая, что в конце программы нам потребуется выполнять сортировку полученных данных, целесообразнее использовать массив записей, поскольку это позволит записать алгоритм сортировки в более компактной форме. Определим запись Street с двумя полями name и max и опишем массив s из 30 элементов типа Street. Следует также завести переменную ns, в которой будет храниться количество заполненных элементов массива s. При обработке каждой строки с исходными данными нам будут нужны прежде всего сведения о марке бензина. Если марка бензина не равна M, то оставшуюся часть строки обрабатывать не требуется, и можно сразу перейти к разбору следующей строки. Если марка бензина равна M, то необходимо узнать название улицы s0 и цену бензина p. Заметим, что название компании для решения задачи не требуется, однако его необходимо прочесть, чтобы определить следующий элемент данных — цену бензина. Если улица с названием s0 еще не была включена в массив s, то ее необходимо включить в массив, присвоив полю max значение p. Если же улица уже присутствует в массиве, то необходимо сравнить поле max для данной улицы и значение p, изменив при необходимости поле max (здесь мы используем базовый алгоритм нахождения максимального значения). Для ввода названий улиц и компаний в нашем случае удобно организовать посимвольное чтение строковых данных; признаком завершения такого чтения будет обнаружение пробельного символа. После обработки набора исходных данных необходимо проверить, найдена ли хотя бы одна улица с АЗС, предлагающей марку бензина M (для этого достаточно сравнить значение ns с нулем). Если ни одна улица не найдена, то надо вывести строку «No»; в противном случае требуется выполнить сортировку массива s по указанному набору ключей и вывести полученные данные в требуемом порядке. Поскольку размер массива невелик, для его сортировки вполне допустимо использовать один из простых алгоритмов, например, алгоритм пузырьковой сортировки. Приведем один из вариантов правильного решения задачи: {$mode delphi}{$H+}
program ExamExt53;
uses
PT4Exam;
// Для ввода используйте процедуру Read или Readln
// Для вывода используйте процедуру Write или Writeln
// Между полученными результатами надо выводить символ пробела
type
Street = record
name: string;
max: integer;
end;
var
m, n, ns, i, j, k, p: integer;
s: array[1..30] of Street;
s0: string;
x: Street;
c: char;
begin
Task('ExamExt53');
Readln(m); { m - марка бензина }
Readln(n);
ns := 0;
for i := 1 to n do
begin
Read(k);
if k <> m then
Readln { пропускаем оставшуюся часть строки }
else
begin
s0 := '';
Read(c); { пропускаем пробел после первого числа }
Read(c); { читаем первый символ названия улицы }
while c <> ' ' do
begin
s0 := s0 + c;
Read(c);
end;
Read(c); { читаем первый символ названия компании }
while c <> ' ' do
Read(c); { название компании не сохраняем }
Readln(p); { читаем цену бензина и переходим на новую строку }
{ Обработка прочитанной информации }
k := 0;
for j := 1 to ns do
if s[j].name = s0 then { улица уже содержится в массиве s }
begin
k := 1;
if s[j].max < p then
s[j].max := p;
break;
end;
if k = 0 then { улица еще не содержится в массиве s }
begin
Inc(ns);
s[ns].name := s0;
s[ns].max := p;
end;
end;
end;
if ns = 0 then { ни одной улицы не найдено }
Writeln('No')
else
begin
{ Сортировка по возрастанию максимальной цены,
а для одинаковых цен - по названиям улиц }
for k := 1 to ns - 1 do
for i := 1 to ns - k do
if (s[i].max > s[i + 1].max) or
(s[i].max = s[i + 1].max) and
(s[i].name > s[i + 1].name) then
begin
x := s[i];
s[i] := s[i + 1];
s[i + 1] := x;
end;
{ Вывод результатов в требуемом порядке }
for i := 1 to ns do
Writeln(s[i].max,' ',s[i].name);
end;
end.
Решение с файловым вводом исходных данныхКак и для предыдущей задачи, приведем решение, в котором используется ввод данных из текстового файла (соответствующая задача имеет имя ExamFExt53). {$mode delphi}{$H+}
program ExamFExt53;
uses PT4ExamTasks;
// Исходные данные следует вводить с помощью процедур файлового ввода
// Для вывода используйте процедуру Write или Writeln
// Между полученными результатами надо выводить символ пробела
type
Street = record
name: string;
max: integer;
end;
var
filename: string;
f : text;
m, n, ns, i, j, k, p: integer;
s: array[1..30] of Street;
s0: string;
x: Street;
c: char;
begin
Task('ExamFExt53');
filename := GetString; // имя исходного файла
Assign(f,filename);
Reset(f);
Readln(f, m, n); { m - марка бензина }
ns := 0;
for i := 1 to n do
begin
Read(f, k);
if k <> m then
Readln(f) { пропускаем оставшуюся часть строки }
else
begin
s0 := '';
Read(f, c); { пропускаем пробел после первого числа }
Read(f, c); { читаем первый символ названия улицы }
while c <> ' ' do
begin
s0 := s0 + c;
Read(f, c);
end;
Read(f, c); { читаем первый символ названия компании }
while c <> ' ' do
Read(f, c); { название компании не сохраняем }
Readln(f, p); { читаем цену бензина и переходим на новую строку }
{ Обработка прочитанной информации }
k := 0;
for j := 1 to ns do
if s[j].name = s0 then { улица уже содержится в массиве s }
begin
k := 1;
if s[j].max < p then
s[j].max := p;
break;
end;
if k = 0 then { улица еще не содержится в массиве s }
begin
Inc(ns);
s[ns].name := s0;
s[ns].max := p;
end;
end;
end;
Close(f);
if ns = 0 then { ни одной улицы не найдено }
Writeln('No')
else
begin
{ Сортировка по возрастанию максимальной цены,
а для одинаковых цен - по названиям улиц }
for k := 1 to ns - 1 do
for i := 1 to ns - k do
if (s[i].max > s[i + 1].max) or
(s[i].max = s[i + 1].max) and
(s[i].name > s[i + 1].name) then
begin
x := s[i];
s[i] := s[i + 1];
s[i + 1] := x;
end;
{ Вывод результатов в требуемом порядке }
for i := 1 to ns do
Writeln(s[i].max,' ',s[i].name);
end;
end.
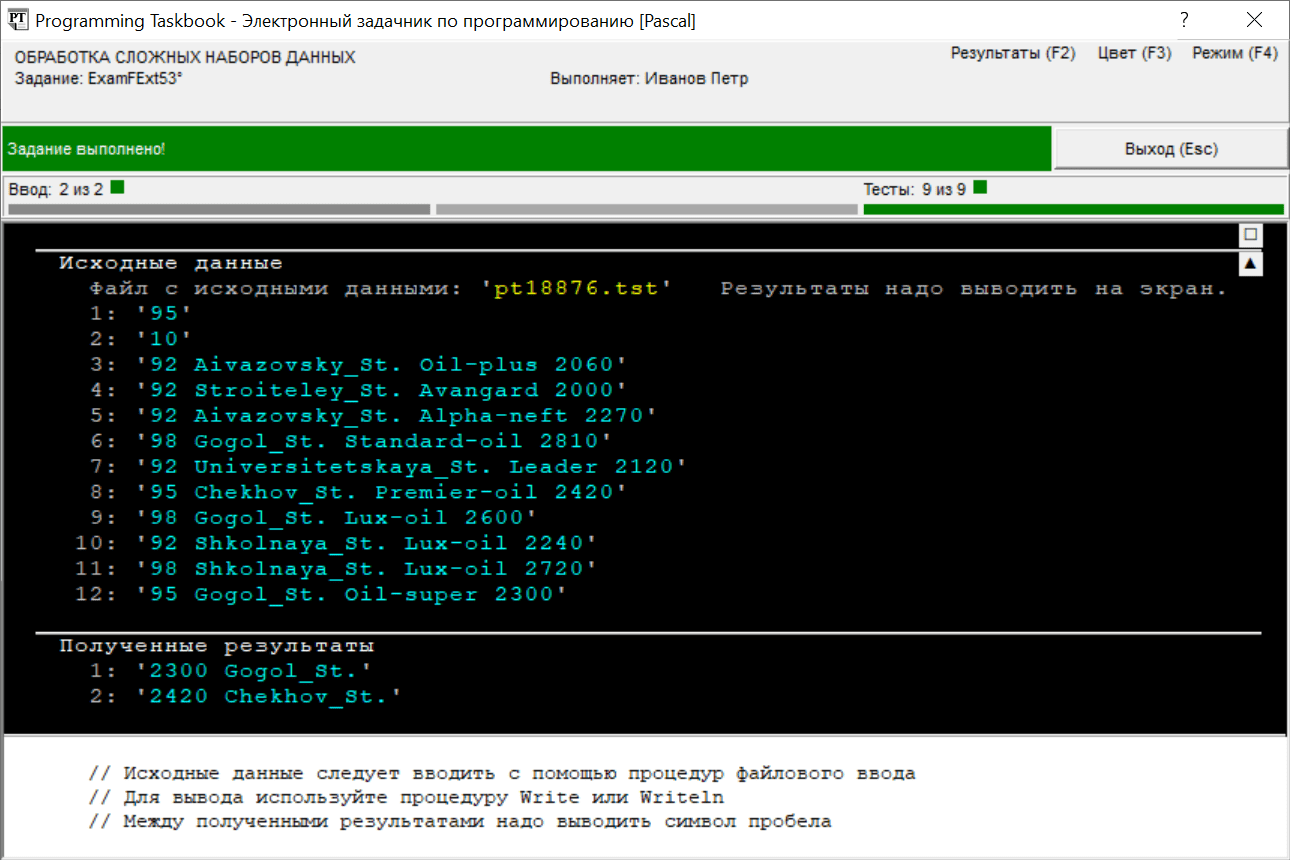
После проверки программы на девяти наборах тестовых данных будет выведено сообщение о том, что задание выполнено:
|
|
|
Разработка сайта: |
Последнее обновление: |