|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
Простое задание на обработку отдельной последовательности: LinqObj4Создание проекта-заготовки и знакомство с заданием. Дополнительные средства окна задачника, связанные с просмотром файловых данныхЗадания группы LinqObj предназначены для закрепления навыков применения различных методов интерфейса LINQ to Objects. В отличие от заданий группы LinqBegin эти задания не ориентированы на изучение какого-либо отдельного вида запросов; при их выполнении требуется самостоятельно выбрать методы LINQ, обеспечивающие получение требуемого результата. Еще одним отличием от заданий группы LinqBegin является более сложный вид исходных последовательностей: их элементы представляют собой записи, состоящие из нескольких полей. Указанные особенности приближают задания группы LinqObj к реальным задачам, возникающим при обработке сложных структур данных. Мы рассмотрим сравнительно простую задачу, связанную с обработкой отдельной последовательности. LinqObj4°. Исходная последовательность содержит сведения о клиентах фитнес-центра. Каждый элемент последовательности включает следующие целочисленные поля: <Год> <Номер месяца> <Продолжительность занятий (в часах)> <Код клиента> Для каждого клиента, присутствующего в исходных данных, определить суммарную продолжительность занятий в течение всех лет (вначале выводить суммарную продолжительность, затем код клиента). Сведения о каждом клиенте выводить на новой строке и упорядочивать по убыванию суммарной продолжительности, а при их равенстве — по возрастанию кода клиента. Проект-заготовка для данного задания, как и для любых заданий, выполняемых с использованием электронного задачника Programming Taskbook, должен создаваться с помощью программного модуля PT4Load. После создания этого проекта, автоматического запуска среды Visual Studio и загрузки в нее созданного проекта на экране будет отображен файл LinqObj4.cs, в который требуется ввести решение задачи. Приведем содержимое этого файла: // File: "LinqObj4"
using PT4;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.IO;
namespace PT4Tasks
{
public class MyTask : PT
{
// To read strings from the source text file into
// a string sequence (or array) s, use the statement:
// s = File.ReadLines(GetString());
// To write the sequence s of IEnumerable<string> type
// into the resulting text file, use the statement:
// File.WriteAllLines(GetString(), s);
// When solving tasks of the LinqObj group, the following
// additional methods defined in the taskbook are available:
// (*) Show() and Show(cmt) (extension methods) - debug output
// of a sequence, cmt - string comment;
// (*) Show(e => r) and Show(cmt, e => r) (extension methods) -
// debug output of r values, obtained from elements e
// of a sequence, cmt - string comment.
public static void Solve()
{
Task("LinqObj4");
}
}
}
По сравнению с файлами, создаваемыми для решения задач группы LinqBegin, файлы-заготовки для задач группы LinqObj имеют следующие особенности:
При выполнении заданий из группы LinqObj нет необходимости в использовании
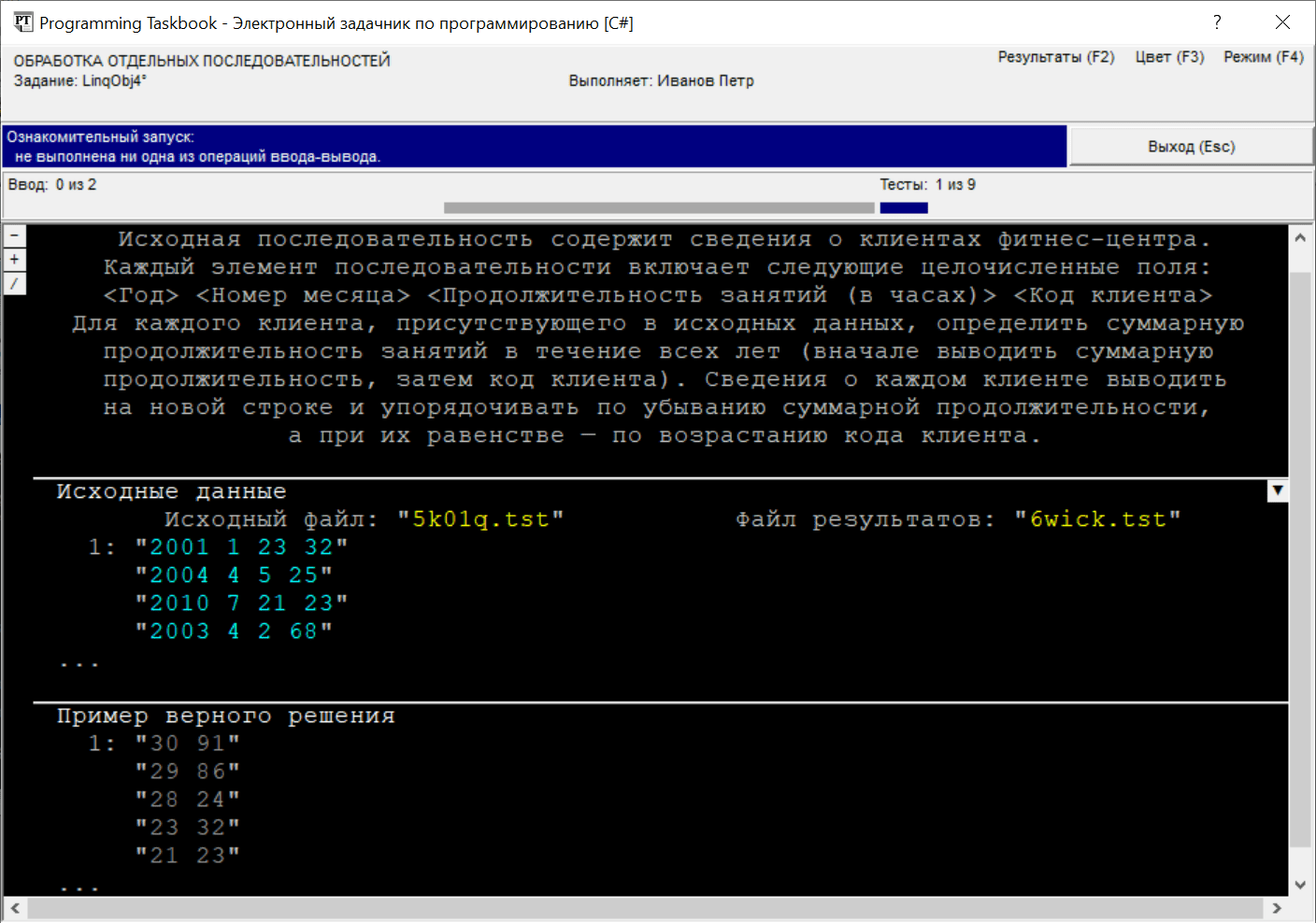
методов ввода-вывода Запустив созданную программу-заготовку, мы увидим на экране окно задачника, содержащее формулировку задания, а также пример исходных данных и правильных результатов:
Как при ознакомительном запуске любого задания, окно содержит три раздела: с формулировкой задания, исходными данными и примером верного решения. В начале раздела с исходными данными указаны две текстовые строки, снабженные комментариями «Исходный файл» и «Файл результатов». Первая строка определяет имя текстового файла, содержащего исходную последовательность. Этот файл автоматически создается задачником при инициализации задания; получив его имя, программа учащегося сможет обратиться к нему и прочесть его данные. Вторая строка определяет имя текстового файла, в котором должна содержаться результирующая строковая последовательность. Программа учащегося должна заполнить указанный файл требуемыми данными, после чего задачник проанализирует содержимое этого файла, сравнив его с правильным вариантом решения. При каждом тестовом запуске имена файлов, как и их содержимое, изменяются. В окне задачника отображаются не только имена, но и содержимое файлов, связанных с заданием. Каждая строка текстового файла заключается в кавычки и выводится на отдельной экранной строке; рядом с первой строкой файла указывается ее порядковый номер, равный 1. В разделах исходных данных и результатов содержимое файлов выделяется бирюзовым цветом (цветовое выделение позволяет отличить файловые строки от других данных, а также комментариев). В разделе с правильным решением все данные выводятся серым цветом, чтобы отличить их от «настоящих» данных, найденных программой учащегося. Приведенный на предыдущем рисунке вариант окна соответствует режиму сокращенного отображения файловых данных, в котором для каждого файла отображается лишь начальная часть его содержимого (от одной до пяти строк). Признаком того, что часть данных отсутствует, является многоточие, размещенное в нижней части тех разделов, в которых отображаются сокращенные данные. Этот режим удобен при первоначальном знакомстве с заданием, поскольку позволяет отобразить в окне сравнительно небольшого размера содержимое всех разделов. При более детальном анализе данных, а также при сравнении полученных ошибочных результатов с примером правильного решения следует использовать режим полного отображения содержимого текстовых файлов. Завершающая часть данного раздела будет посвящена описанию различных возможностей, связанных с режимом полного отображения. Для переключения между сокращенным и полным режимом
отображения файловых данных достаточно нажать клавишу [Ins] или
выполнить двойной щелчок мышью в одном из разделов с файловыми
данными. Можно также щелкнуть на квадратном маркере, который
появляется в правом верхнем углу раздела исходных данных, если окно
содержит файловые данные. Изображение на этом маркере служит
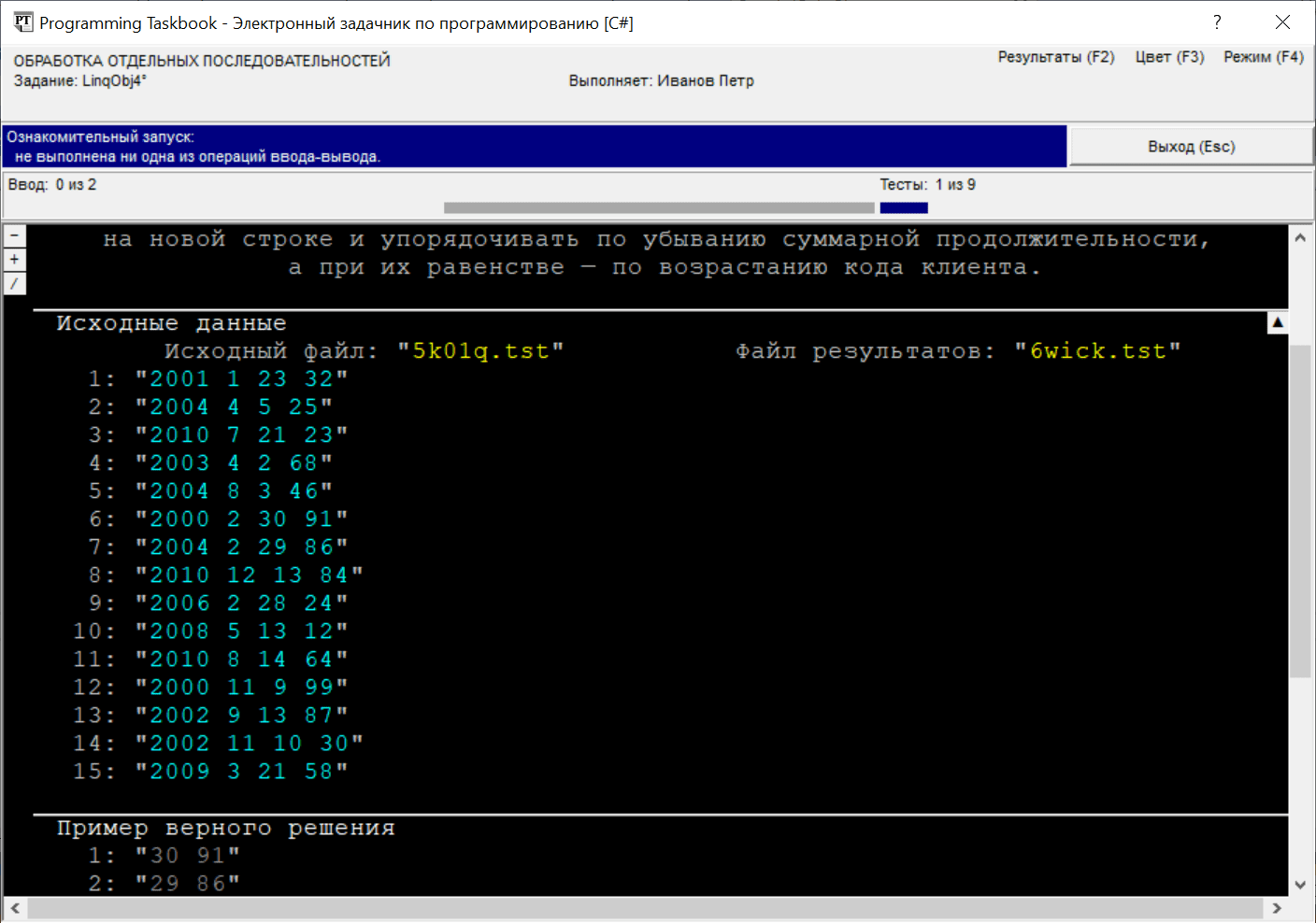
индикатором режима: вариант На следующем рисунке приведен вид окна в режиме полного отображения текстовых файлов. В этом режиме порядковый номер указывается перед каждой файловой строкой. При закрытии окна текущий режим отображения запоминается и при последующих запусках программы восстанавливается.
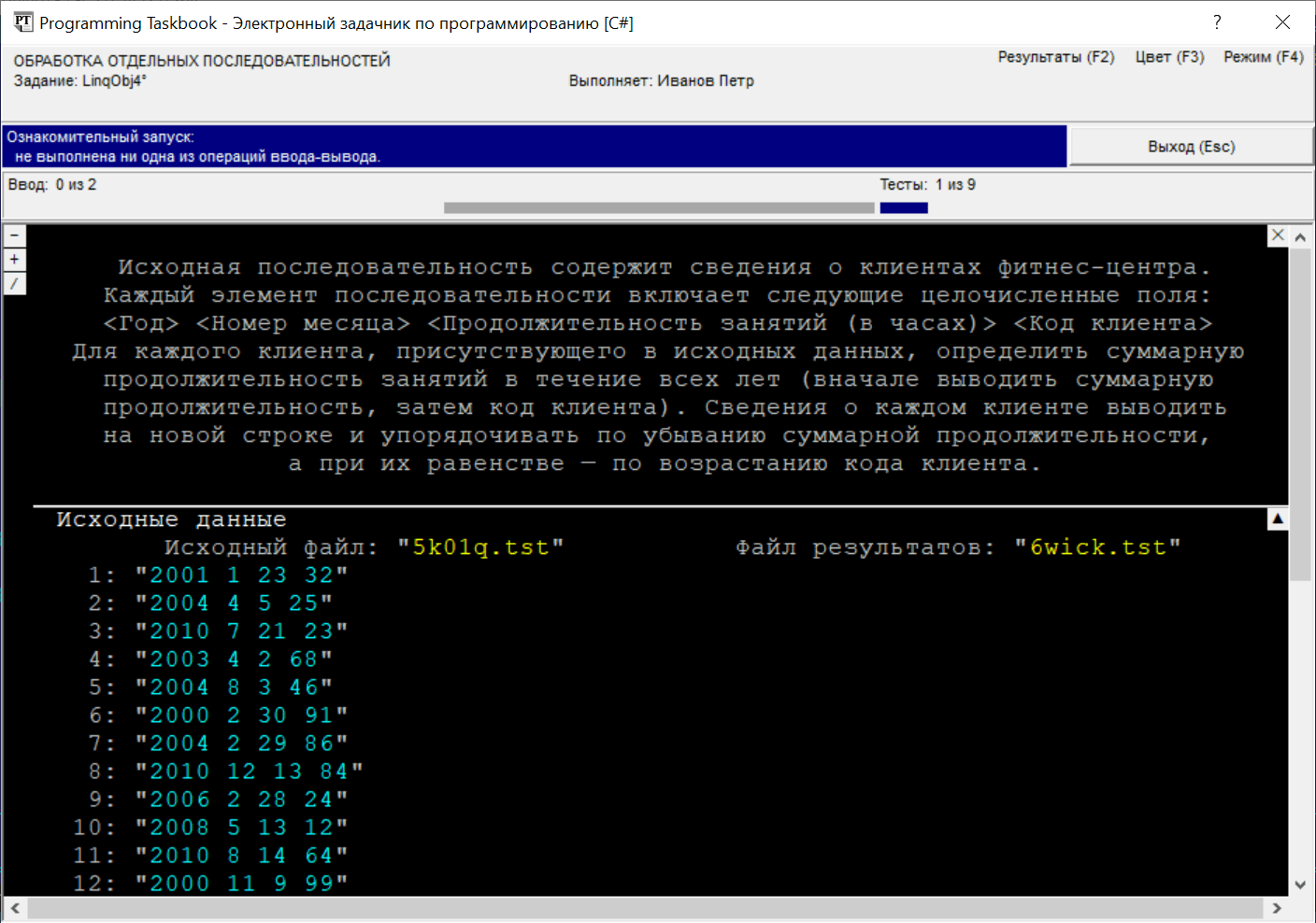
В случае, когда размеров окна недостаточно для отображения всех данных, окно снабжается полосой прокрутки, и, кроме того, на нем отображаются дополнительные маркеры (см. рисунок). Прокрутку содержимого окна проще всего выполнять с помощью клавиш [Home], [End], [Up], [Down], [PgUp], [PgDn], а также используя колесико мыши.
Группа маркеров, отображаемая в левом верхнем углу раздела с
формулировкой задания, предназначена для быстрого отображения
различных разделов, связанных с заданием: щелчок на маркере
Наконец, отметим маркер Выполнение заданияЗавершив обзор дополнительных возможностей окна задачника и ознакомившись с заданием LinqObj4, приступим к его выполнению. В этом задании, как и во всех заданиях группы LinqObj, исходная
последовательность содержится во внешнем текстовом файле. Для чтения
всех строк этого файла проще всего воспользоваться методом File.ReadLines(GetString()) Первый параметр этого метода определяет имя файла; мы получаем
это имя с помощью функции
Примечание. При использовании метода При последующей обработке исходной последовательности нам
будет нужно обращаться к отдельным полям ее элементов, поэтому после
считывания строк из исходного файла необходимо преобразовать их в
набор полей. Для этого достаточно применить к полученному строковому
массиву метод File.ReadLines(GetString())
.Select(e =>
{
string[] s = e.Split(' ');
return new
{
hours = int.Parse(s[2]),
code = int.Parse(s[3])
};
})
Мы использовали лямбда-выражение, содержащее не возвращаемое
значение, а набор операторов, включающий оператор Возможен и вариант лямбда-выражения с возвращаемым значением,
но в нем требуется дважды выполнить вызов метода .Select(e => new
{
hours = int.Parse(e.Split[2]),
code = int.Parse(e.Split[3])
})
Такой вариант вполне допустим для простых наборов данных, содержащих небольшое число полей. Заметим, что мы включили в анонимный тип лишь данные, связанные
с продолжительностью занятий (поле На данном этапе решения задачи можно выполнить отладочный
вывод полученной последовательности, добавив к цепочке вызванных
методов вспомогательный метод public static void Solve()
{
Task("LinqObj4");
File.ReadLines(GetString())
.Select(e =>
{
string[] s = e.Split(' ');
return new
{
hours = int.Parse(s[2]),
code = int.Parse(s[3])
};
})
.Show();
}
При запуске программы в окне задачника появится раздел отладки, содержащий информацию о полученной последовательности. Приведем вид этого окна в режиме сокращенного отображения файловых данных, дополнительно скрыв раздел с формулировкой. Информационная панель содержит сообщение «Введены не все требуемые исходные данные», поскольку в нашей программе еще не введено имя файла результатов.
Раздел отладки демонстрирует, каким образом данные анонимного типа
преобразуются к их строковому представлению: это представление
содержит список пар В задании требуется определить суммарную продолжительность
занятий для каждого клиента; для этого следует выполнить группировку
полученной последовательности по кодам клиентов. Затем надо
отсортировать сгруппированную последовательность по двум
ключам: главному (суммарная продолжительность) — по убыванию и
подчиненному (код клиента) — по возрастанию. Отсортированную
последовательность надо преобразовать в последовательность строк с
помощью метода проецирования Используя простейший вариант метода .GroupBy(e => e.code) .OrderByDescending(e => e.Sum(c => c.hours)) .ThenBy(e => e.Key) .Select(e => e.Sum(c => c.hours) + " " + e.Key) В приведенном варианте приходится дважды вычислять сумму полей
.GroupBy(e => e.code,
(k, ee) => new {k, sum = ee.Sum(c => c.hours)})
.OrderByDescending(e => e.sum).ThenBy(e => e.k)
.Select(e => e.sum + " " + e.k)
В выражении, использованном в методе Осталось записать полученную строковую последовательность в
текстовый файл с указанным именем. Если предварительно связать
последовательность с переменной File.WriteAllLines(GetString(), r); При выполнении данного оператора вначале определяется имя файла результатов, которое считывается
из набора исходных данных с помощью функции Объединяя полученные фрагменты, получаем первый вариант правильного решения: public static void Solve()
{
Task("LinqObj4");
var r = File.ReadLines(GetString())
.Select(e =>
{
string[] s = e.Split(' ');
return new
{
hours = int.Parse(s[2]),
code = int.Parse(s[3])
};
})
.GroupBy(e => e.code,
(k, ee) => new { k, sum = ee.Sum(c => c.hours) })
.OrderByDescending(e => e.sum).ThenBy(e => e.k)
.Select(e => e.sum + " " + e.k);
File.WriteAllLines(GetString(), r);
}
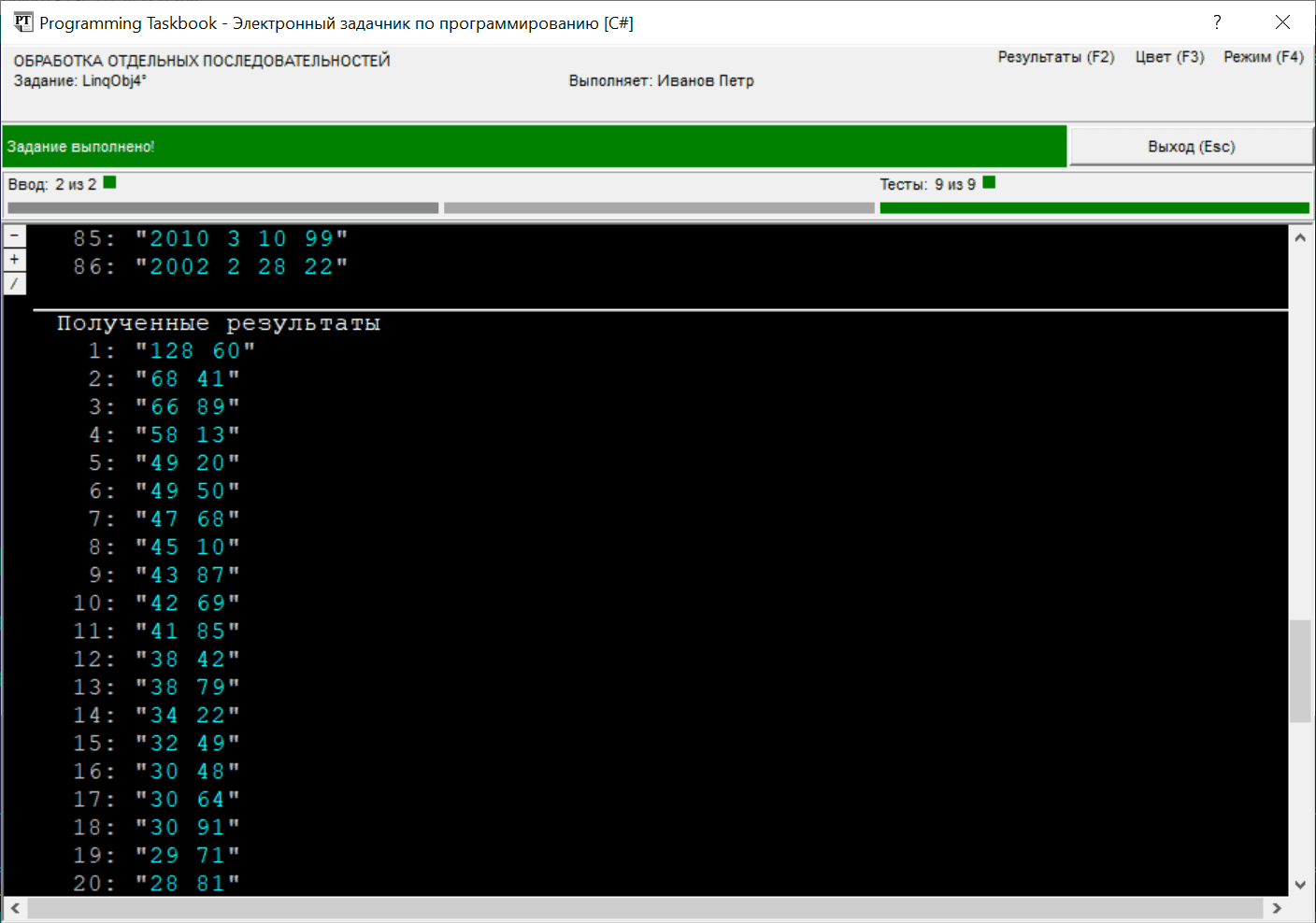
Для проверки правильности полученного решения (как и решений других задач группы LinqObj) его надо протестировать на девяти различных тестовых наборах исходных данных, среди которых будут встречаться и наборы сравнительно большого размера. В качестве примера приведем окно задачника с сообщением об успешном выполнении задания, в котором для обработки был предложен набор из 86 записей:
Завершая обсуждение задания LinqObj4, приведем вариант его решения, использующий выражение запросов: public static void Solve()
{
Task("LinqObj4");
var r =
from e in File.ReadLines(GetString())
let s = e.Split(' ')
select new
{
hours = int.Parse(s[2]),
code = int.Parse(s[3])
}
into e
group e.hours by e.code
into e
let sum = e.Sum()
orderby sum descending, e.Key
select sum + " " + e.Key;
File.WriteAllLines(GetString(), r);
}
Прокомментируем особенности данного варианта. Поскольку в конструкции Результаты выполнения конструкций Конструкция Полученный вариант решения обладает несколько большей наглядностью, чем первый вариант, прежде всего, за счет отсутствия лямбда-выражений.
|
 со стрелкой, направленной вниз,
обозначает режим сокращенного отображения (при наведении мыши на
маркер в этом случае выводится подсказка «Развернуть содержимое
текстовых файлов (Ins)»); вариант
со стрелкой, направленной вниз,
обозначает режим сокращенного отображения (при наведении мыши на
маркер в этом случае выводится подсказка «Развернуть содержимое
текстовых файлов (Ins)»); вариант  со стрелкой, направленной вверх,
обозначает режим полного отображения (с ним связана подсказка
«Свернуть содержимое текстовых файлов (Ins)»).
со стрелкой, направленной вверх,
обозначает режим полного отображения (с ним связана подсказка
«Свернуть содержимое текстовых файлов (Ins)»).
 обеспечивает переход к началу следующего раздела (см. рисунок), щелчок на
маркере
обеспечивает переход к началу следующего раздела (см. рисунок), щелчок на
маркере  — к началу предыдущего раздела. Перебор разделов
выполняется циклически. Маркер
— к началу предыдущего раздела. Перебор разделов
выполняется циклически. Маркер  позволяет переключаться между
разделами с результатами и примером правильного решения, если окно
содержит оба этих раздела. Вместо щелчка на указанных маркерах
достаточно нажать соответствующую клавишу: [+], [–] или [/].
позволяет переключаться между
разделами с результатами и примером правильного решения, если окно
содержит оба этих раздела. Вместо щелчка на указанных маркерах
достаточно нажать соответствующую клавишу: [+], [–] или [/].
 , появляющийся в правом верхнем углу
раздела с формулировкой задания при отображении в окне полосы
прокрутки. Этот маркер (и связанная с ним клавиша [Del]) позволяет
скрыть раздел с формулировкой, увеличив тем самым область окна для
отображения данных из других разделов. Заметим, что клавиша [Del]
позволяет скрыть раздел с формулировкой и в том случае, если маркер
, появляющийся в правом верхнем углу
раздела с формулировкой задания при отображении в окне полосы
прокрутки. Этот маркер (и связанная с ним клавиша [Del]) позволяет
скрыть раздел с формулировкой, увеличив тем самым область окна для
отображения данных из других разделов. Заметим, что клавиша [Del]
позволяет скрыть раздел с формулировкой и в том случае, если маркер 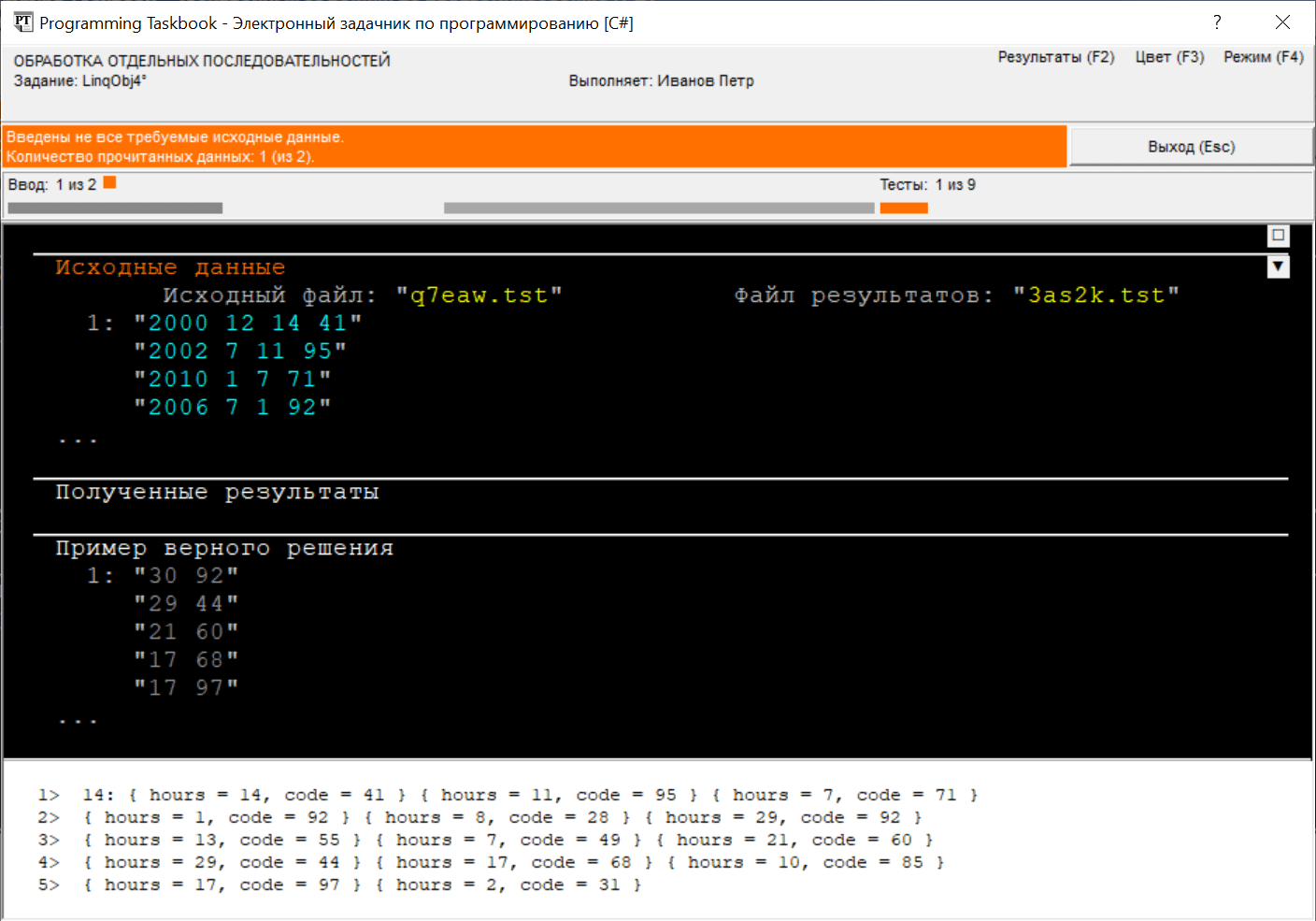
|
|
Разработка сайта: |
Последнее обновление: |