|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
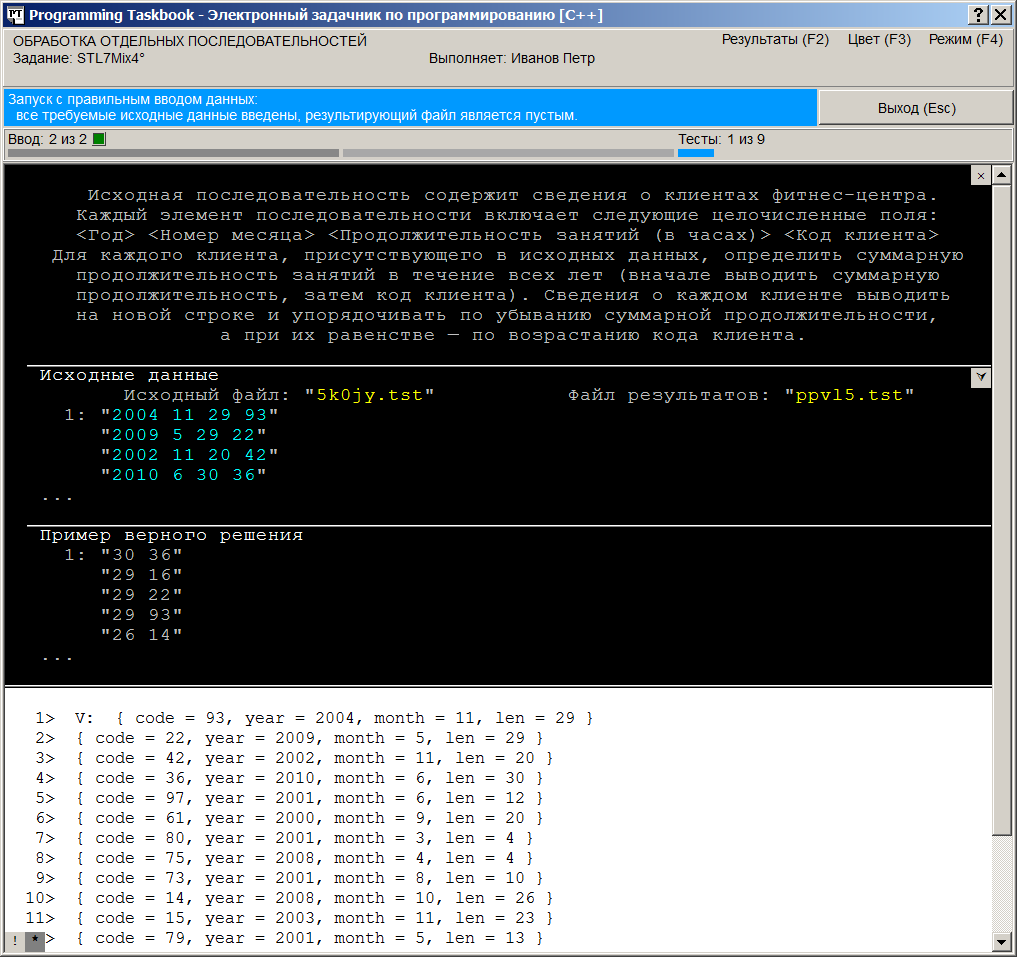
Применение различных средств стандартной библиотеки C++: STL7Mix4Создание проекта-заготовки и знакомство с заданием. Дополнительные средства окна задачника, связанные с просмотром файловых данныхГруппа STL7Mix является завершающей группой, входящей в задачник Programming Taskbook for STL. Каждая из предыдущих групп задачника посвящена отдельной части стандартной библиотеки: итераторам, последовательным контейнерам, алгоритмам, строкам, ассоциативным контейнерам, функциональным объектам. Задания группы STL7Mix предназначены для развития и закрепления навыков совместного использования различных компонентов библиотеки STL; при их выполнении требуется самостоятельно выбрать средства библиотеки, обеспечивающие получение требуемого результата. Еще одним отличием заданий последней группы является более сложный вид исходных последовательностей: их элементы представляют собой записи, состоящие из нескольких полей. Указанные особенности приближают задания группы STL7Mix к реальным задачам, возникающим при обработке сложных структур данных. Набор заданий, входящих в группу STL7Mix, ранее был использован в задачнике Programming Taskbook for LINQ в качестве группы LinqObj. Задачник Programming Taskbook for LINQ предназначен для изучения технологии LINQ, доступной для языков платформы .NET (C#, VB.NET, PascalABC.NET) и призванной упростить решение тех же задач, для которых была разработана библиотека STL, а именно, задач, связанных с обработкой последовательностей. Благодаря совпадающим формулировкам задач групп STL7Mix и LinqObj, их можно использовать для сравнительного изучения на практике обеих технологий, что позволит глубже понять их основные идеи и особенности. В частности, можно сравнить способы решения задачи STL7Mix4 и LinqObj4, приведенные в справочных системах к этим задачникам. Итак, обратимся к задаче STL7Mix4. Это сравнительно простая задача, связанная с обработкой отдельной последовательности. STL7Mix4°. Исходная последовательность содержит сведения о клиентах фитнес-центра. Каждый элемент последовательности включает следующие целочисленные поля: <Год> <Номер месяца> <Продолжительность занятий (в часах)> <Код клиента> Для каждого клиента, присутствующего в исходных данных, определить суммарную продолжительность занятий в течение всех лет (вначале выводить суммарную продолжительность, затем код клиента). Сведения о каждом клиенте выводить на новой строке и упорядочивать по убыванию суммарной продолжительности, а при их равенстве - по возрастанию кода клиента. Указание. Для группировки по полю «код» используйте вспомогательное отображение. Проект-заготовка для данного задания, как и для любых заданий, выполняемых с использованием электронного задачника Programming Taskbook, должен создаваться с помощью программного модуля PT4Load. После создания этого проекта, автоматического запуска среды Visual Studio и загрузки в нее созданного проекта на экране будет отображен файл STL7Mix4.cpp, в который требуется ввести решение задачи. Приведем содержимое этого файла: #include "pt4.h"
using namespace std;
#include <fstream>
#include <sstream>
#include <iomanip>
#include <algorithm>
#include <vector>
#include <set>
#include <map>
struct Data
{
int code, year, month, len;
operator string()
{
ostringstream os;
os << "{ code = " << code << ", year = " << year
<< ", month = " << month << ", len = " << len << " }";
return os.str();
}
};
istream& operator>>(istream& is, Data& p)
{
return is >> p.year >> p.month >> p.len >> p.code;
}
void Solve()
{
Task("STL7Mix4");
string name1, name2;
pt >> name1 >> name2;
ifstream f1(name1);
vector<Data> V((istream_iterator<Data>(f1)), istream_iterator<Data>());
f1.close();
ShowLine(V.begin(), V.end(), "V: ");
ofstream f2(name2);
f2.close();
}
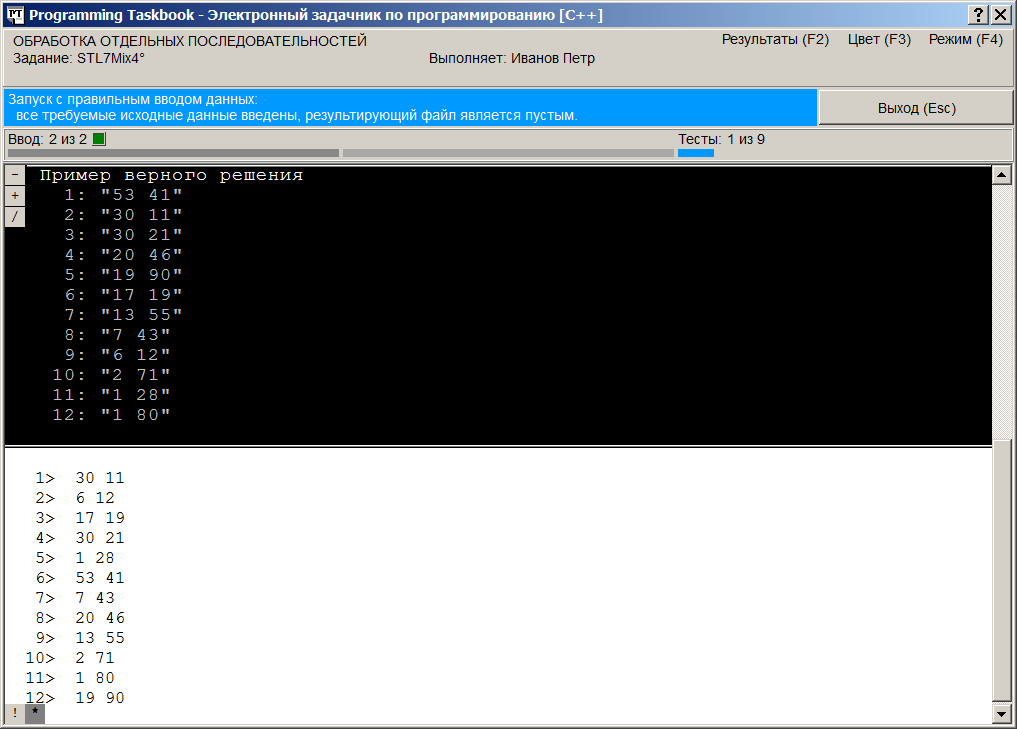
Тексты заготовок для заданий группы STL7Mix являются еще более развернутыми, чем заготовки для предыдущих групп задачника PT for STL. Напомним, что в группе STL1Iter использовались простейшие заготовки, содержащие минимально необходимый набор инструкций #include и описание функции Solve, включающее лишь вызов функции Task. В последующих группах заготовки включали описание используемых контейнеров и даже ввод в них исходных данных. Это избавляло учащегося от стандартных начальных действий (уже отработанных при выполнении предыдущих заданий) и позволяло сразу сосредоточиться на смысловой части алгоритма. Подобные цели преследуют и развернутые заготовки группы STL7Mix. Они не просто обеспечивают ввод исходных данных (хранящихся во внешних файлах), но и позволяют сохранить эти данные в векторе, причем каждый элемент данных представляется в виде структуры Data, также определенной в заготовке. Помимо полей в этой структуре определен оператор преобразования структуры в строку, что дает возможность использовать шаблонный вариант функции ShowLine для быстрого вывода полученной последовательности структур в разделе отладки окна задачника (причем вызов этого варианта функции ShowLine уже присутствует в заготовке). Для организации ввода исходных данных с применением итераторов файловых потоков в программе переопределяется оператор >> для структуры Data (следует обратить внимание на конструктор вектора V, содержащий два параметра-итератора, первый из которых заключен в дополнительные круглые скобки; причина этого объясняется в указании к заданию STL2Seq1). Наконец, в состав заготовки включены и все операторы, обеспечивающие открытие и закрытие используемых текстовых файлов. Следует заметить, что в стандарте C++11 появилась возможность использования параметров типа string в конструкторах потоков; таким образом, в современных версиях языка можно было обойтись без вызова функции c_str для строковых параметров данных конструкторов. Имея такую заготовку, мы можем сразу приступить к реализации содержательной части программы: обработке исходной последовательности (уже доступной в виде вектора типа vector<Data>) с целью получения результирующей последовательности и ее вывода в текстовый файл в нужном формате. После запуска созданной программы-заготовки мы увидим на экране окно задачника, содержащее формулировку задания, пример исходных данных и правильных результатов, а также строковые представления всех элементов исходного набора, выведенные функцией ShowLine в разделе отладки.
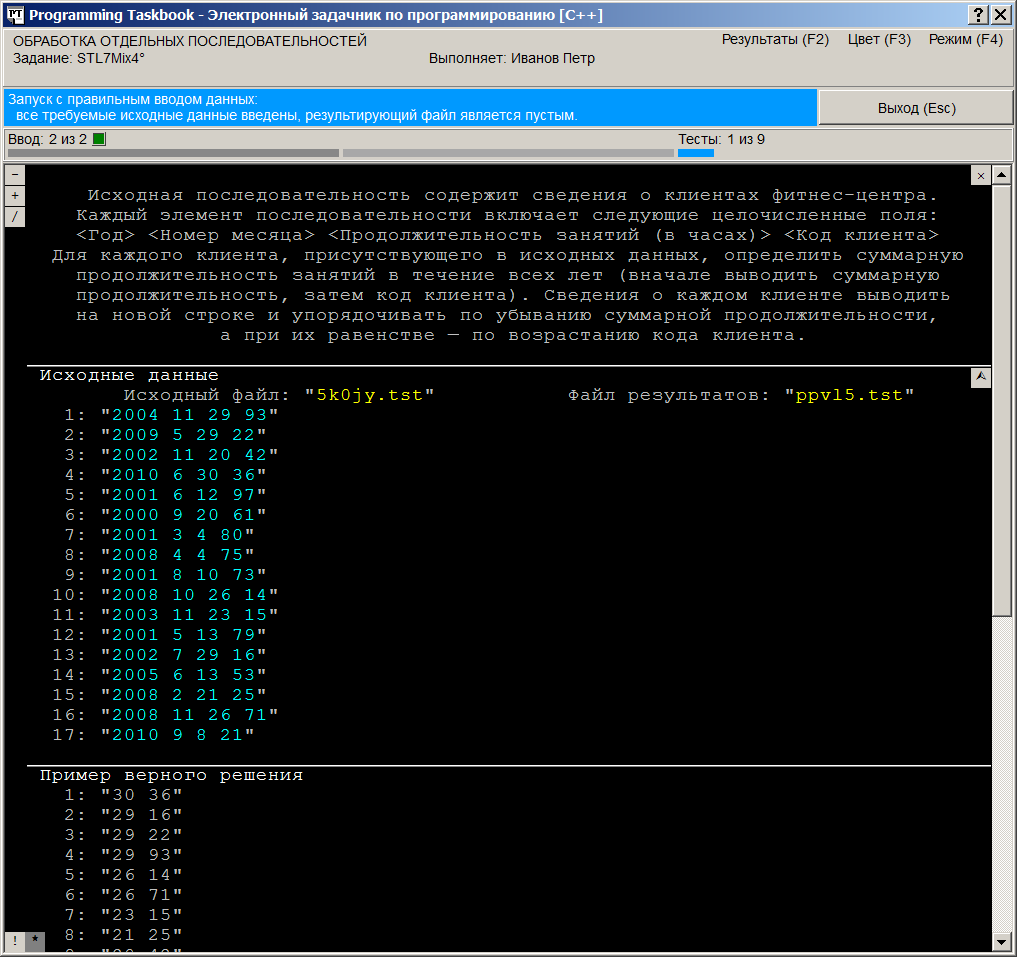
На информационной панели (светло-синего цвета) отмечается, что все исходные данные введены, а файл результатов является пустым. Таким образом, все готово для реализации алгоритма обработки исходных данных. Однако прежде, чем переходить к описанию собственно процесса решения, напомним о некоторых возможностях окна задачника, которые могут оказаться полезными при анализе исходных и результирующих данных, представленных в виде текстовых файлов большого размера. Каждая строка текстового файла заключается в кавычки и выводится на отдельной экранной строке; рядом с первой строкой файла указывается ее порядковый номер, равный 1. В разделах исходных данных и результатов содержимое файлов выделяется бирюзовым цветом (цветовое выделение позволяет отличить файловые строки от других данных, а также комментариев). В разделе с правильным решением все данные выводятся серым цветом, чтобы отличить их от «настоящих» данных, найденных программой учащегося. Приведенный на предыдущем рисунке вариант окна соответствует режиму сокращенного отображения файловых данных, в котором для каждого файла отображается лишь начальная часть его содержимого (от одной до пяти строк). Признаком того, что часть данных отсутствует, является многоточие, размещенное в нижней части тех разделов, в которых отображаются сокращенные данные. Этот режим удобен при первоначальном знакомстве с заданием, поскольку позволяет отобразить в окне сравнительно небольшого размера содержимое всех разделов. При более детальном анализе данных, а также при сравнении полученных ошибочных результатов с примером правильного решения следует использовать режим полного отображения содержимого текстовых файлов. Для переключения между сокращенным и полным режимом отображения файловых
данных достаточно нажать клавишу [Ins] или выполнить двойной щелчок мышью в одном
из разделов с файловыми данными. Можно также щелкнуть на квадратном маркере,
который появляется в правом верхнем углу раздела исходных данных, если окно
содержит файловые данные. Изображение на этом маркере служит индикатором режима:
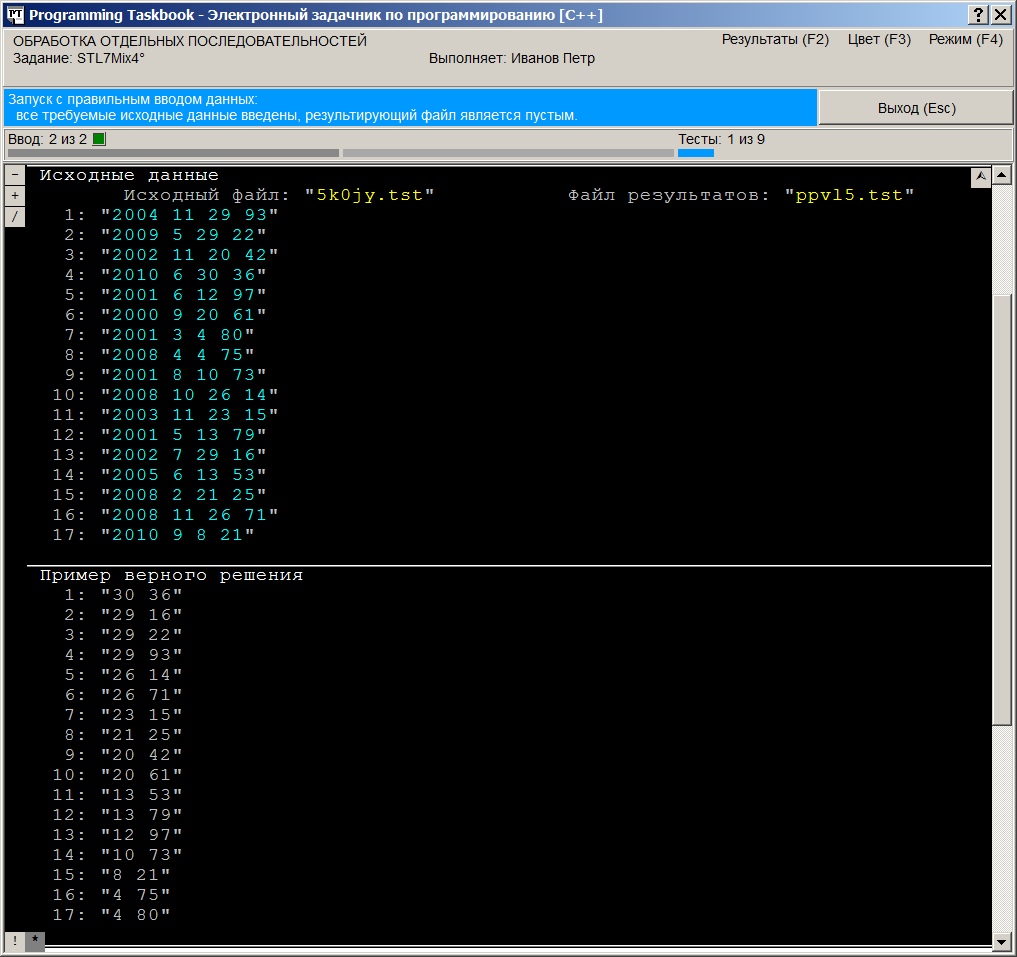
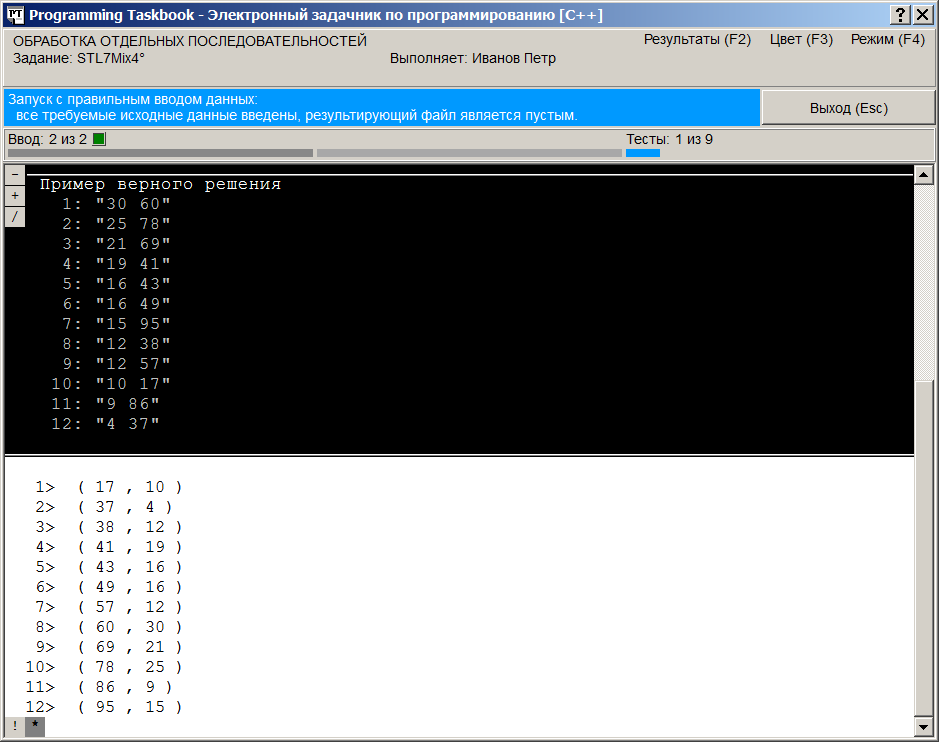
вариант На следующем рисунке приведен вид окна в режиме полного отображения текстовых файлов. В этом режиме порядковый номер указывается перед каждой файловой строкой. При закрытии окна текущий режим отображения запоминается и при последующих запусках программы восстанавливается.
В случае, когда размеров окна недостаточно для отображения всех данных, окно снабжается полосой прокрутки, и, кроме того, на нем отображаются дополнительные маркеры (см. предыдущий рисунок). Прокрутку содержимого окна проще всего выполнять с помощью клавиш [Home], [End], [Up], [Down], [PgUp], [PgDn], а также используя колесико мыши. Группа маркеров, отображаемая в левом верхнем углу раздела с формулировкой задания,
предназначена для быстрого отображения различных разделов, связанных с заданием:
щелчок на маркере
Обратите внимание на маркер Наконец, следует упомянуть о двух маркерах, которые могут появиться в левом нижнем
углу окна. Это маркеры
Выполнение заданияЗавершив обзор дополнительных возможностей окна задачника и ознакомившись с заданием STL7Mix4, приступим к его выполнению. В процессе обработки исходной последовательности (которая уже хранится в векторе V
типа Способы группировки данных, основанные на контейнерах STL, подробно анализировались в заданиях группы STL5Assoc (см. подгруппу «Отображения. Группировка и объединение данных», включающую задания STL5Assoc15–STL5Assoc36). Один из эффективных способов группировки основан на использовании отображения (map); именно об этом способе напоминает указание к нашему заданию. Определим вспомогательное отображение М с ключом — кодом клиента (целого типа) и значением — суммарной длительностью занятий (также целого типа): map<int, int> M; Для заполнения этого отображения мы должны перебрать все элементы вектора V и для каждого элемента e выполнить следующий оператор: M[e.code] += e.len; Напомним, что в данном операторе используется следующая особенность операции индексирования для отображения: если элемент отображения с указанным ключом не существует, то он автоматически создается, и его значению присваивается значение по умолчанию для данного типа (в нашем случае — число 0). Перебор элементов вектора V можно выполнить различными способами. Опишем два наиболее коротких и наглядных, основанных на новых возможностях, появившихся в стандарте C++11. Первый из этих способов использует алгоритм for_each с лямбда-выражением в качестве функционального объекта: for_each(V.begin(), V.end(), [&M](Data e){M[e.code] += e.len;});
Следует обратить внимание на первый компонент лямбда-выражения: Второй способ является еще более наглядным; он основан на специальном варианте цикла for, предназначенном для перебора элементов некоторого контейнера: for (auto e : V)
M[e.code] += e.len;
Вместо описателя auto, означающего, что компилятор должен сам вывести тип параметра цикла e, исходя из типа элементов контейнера V, можно указать явный описатель Data, однако вариант с auto является более предпочтительным в силу своей универсальности. После выполнения группировки желательно ознакомиться с ее результатами. Проще всего вывести полученные данные в раздел отладки. Чтобы не загромождать этот раздел лишними сведениями, удалим оператор ShowLine, добавленный в программу-заготовку при ее создании. Для вывода в раздел отладки элементов отображения M воспользуемся циклом for (который можно разместить в любом месте программы после операторов, выполняющих группировку): for (auto e : M)
{
Show(e.second);
ShowLine(e.first);
}
При запуске нового варианта программы содержимое отображения M будет выведено в разделе отладки, причем вначале будет выводиться значение каждого элемента, а затем — его ключ. Сравнивая эти данные с примером правильного решения, нетрудно убедиться в том, что группировка выполнена правильно (неверным является лишь порядок следования полученных данных).
Замечание. В версии задачника 4.16 для языка C++ реализованы дополнительные отладочные возможности. В частности, в этой версии можно использовать функции Show и ShowLine для вывода контейнеров, элементами которых являются не только числа или строки, но и пары (можно также выводить контейнеры, элементы которых сами являются контейнерами). Используя эту новую возможность, мы можем упростить приведенный выше фрагмент отладочного вывода отображения M: ShowLine(M.begin(), M.end()); В результате отладочные данные будут выглядеть следующим образом (теперь вначале выводится поле first, а затем — поле second, причем они разделяются запятой и заключаются в круглые скобки):
Итак, мы успешно прошли первый этап решения задачи, выполнив группировку исходных данных. Осталось отсортировать полученные данные в соответствии с условиями задачи. Так как в контейнере map порядок следования элементов фиксирован и определяется значениями ключей (по умолчанию элементы располагаются по возрастанию ключей — см. предыдущий рисунок), для изменения порядка элементов надо скопировать их в контейнер, для которого можно использовать алгоритм сортировки, например, в вектор V1. Тип элементов вектора V1 должен совпадать с типом элементов отображения M, т. е.
typedef pair<int, int> p;
vector<p> V1(M.begin(), M.end());
Для заполненного вектора V1 надо вызвать алгоритм сортировки, передав в него в
качестве последнего параметра функциональный объект, определяющий отношение
сравнения для пары stable_sort(V1.begin(), V1.end(),
[](p e1, p e2){return e1.second > e2.second;});
Данный вариант алгоритма сортирует элементы по убыванию поля second, причем относительное расположение элементов с одинаковыми полями second не изменяется (благодаря устойчивому характеру сортировки). Таким образом, обеспечивается именно такой порядок, который требуется в задаче: элементы располагаются по убыванию поля second (т. е. суммарной длительности), а элементы с одинаковым полем second располагаются по возрастанию поля first (т. е. кода клиента). Осталось вывести отсортированный вектор V1. Для этого можно использовать либо
алгоритм for_each, либо цикл for. Воспользуемся вариантом цикла for, обеспечивающим
перебор элементов последовательности (этот цикл необходимо расположить между
оператором описания потока f2 и оператором его закрытия for (auto e : V1)
f2 << e.second << " " << e.first << endl;
После запуска данного варианта программы и успешного прохождения требуемых девяти тестов будет выведено сообщение о том, что задание выполнено. Приведем функцию Solve с одним из вариантов правильного решения, убрав из нее все операторы отладочного вывода (в тексте функции полужирным шрифтом выделены операторы, которые не содержались в исходном тексте заготовки): void Solve()
{
Task("STL7Mix4");
string name1, name2;
pt >> name1 >> name2;
ifstream f1(name1);
vector<Data> V((istream_iterator<Data>(f1)), istream_iterator<Data>());
f1.close();
map<int, int> M;
for (auto e : V)
M[e.code] += e.len;
typedef pair<int, int> p;
vector<p> V1(M.begin(), M.end());
stable_sort(V1.begin(), V1.end(),
[](p e1, p e2){return e1.second > e2.second;});
ofstream f2(name2);
for (auto e : V1)
f2 << e.second << " " << e.first << endl;
f2.close();
}
Другие варианты решенияРешение было бы более наглядным, если бы поля элементов вектора V1 имели, подобно полям исходного вектора V, значащие имена, например, code (код) и sumlen (суммарная длительность). Этого можно добиться, если ввести вспомогательный тип-структуру с указаными полями. Кроме того, в новом типе (назовем его Res) можно определить дополнительные функции-члены, которые упростят его использование. Итак, опишем следующую структуру: struct Res
{
int code, sumlen;
Res(pair<int, int> p)
{
code = p.first;
sumlen = p.second;
}
bool operator<(Res b) const
{
return this->sumlen > b.sumlen;
}
};
ostream& operator<<(ostream& os, const Res& r)
{
return os << r.sumlen << " " << r.code;
}
В ней, помимо двух полей, определены конструктор, позволяющий неявно преобразовать
пару Замечание. Операцию < можно было бы определить в виде обычной функции (не функции-члена структуры Res): bool operator<(Res a, Res b)
{
return a.len > b.len;
}
Используя тип Res, мы можем получить более наглядный вариант решения задачи, избавившись, к тому же, от лямбда-выражения в алгоритме сортировки (если для сортируемых элементов определена операция <, то в алгоритме сортировки можно не указывать функциональный объект — по умолчанию для сравнения элементов будет применяться операция <): void Solve()
{
Task("STL7Mix4");
string name1, name2;
pt >> name1 >> name2;
ifstream f1(name1.c_str());
vector<Data> V((istream_iterator<Data>(f1)), istream_iterator<Data>());
f1.close();
map<int, int> M;
for (auto e : V)
M[e.code] += e.len;
vector<Res> V1(M.begin(), M.end());
stable_sort(V1.begin(), V1.end());
ofstream f2(name2.c_str());
for (auto e : V1)
f2 << e << endl;
f2.close();
}
Для возможности заполнения вектора V1 данными, взятыми из отображения
M, необходимо, чтобы пару Замечание. Благодаря переопределению операции << для типа Res мы можем организовать запись полученного вектора V1 в файл, используя вместо цикла алгоритм copy в комбинации с итератором ostream_iterator: copy(V1.begin(), V1.end(), ostream_iterator<Res>(f2, "\n")); Для типа Res, как и для типа Data, можно определить операцию приведения к типу string; при этом удобно использовать строковое представление, совпадающее с видом данных, которые требуется записать в результирующий файл: operator string()
{
ostringstream os;
os << sumlen << " " << code;
return os.str();
}
Данную функцию-член необходимо добавить в определение структуры Res. При ее наличии вывод результатов можно оформить, не прибегая к переопределенной для Res операции <<, используя явное приведение к типу string: for (auto e : V1)
f2 << (string)e << endl;
Аналогичный вариант вывода можно использовать и в алгоритме copy: copy(V1.begin(), V1.end(), ostream_iterator<string>(f2, "\n")); Кроме того, наличие операции приведения структуры Res к типу string позволяет использовать функции отладочного вывода Show и ShowLine как для отдельных переменных типа Res, так и для контейнеров с элементами типа Res, например: ShowLine(V1.begin(), V1.end());
|
 со стрелкой, направленной вниз, обозначает режим сокращенного
отображения (при наведении мыши на маркер в этом случае выводится подсказка
«Развернуть содержимое текстовых файлов (Ins)»); вариант
со стрелкой, направленной вниз, обозначает режим сокращенного
отображения (при наведении мыши на маркер в этом случае выводится подсказка
«Развернуть содержимое текстовых файлов (Ins)»); вариант  со стрелкой,
направленной вверх, обозначает режим полного отображения (с ним связана подсказка
«Свернуть содержимое текстовых файлов (Ins)»).
со стрелкой,
направленной вверх, обозначает режим полного отображения (с ним связана подсказка
«Свернуть содержимое текстовых файлов (Ins)»).
 обеспечивает переход к началу следующего раздела (см. следующий
рисунок), щелчок на маркере
обеспечивает переход к началу следующего раздела (см. следующий
рисунок), щелчок на маркере  — к началу предыдущего раздела. Перебор разделов
выполняется циклически. Маркер
— к началу предыдущего раздела. Перебор разделов
выполняется циклически. Маркер  позволяет переключаться между разделами с
результатами и примером правильного решения, если окно содержит оба этих раздела.
Вместо щелчка на указанных маркерах достаточно нажать соответствующую клавишу:
[+], [–] или [/].
позволяет переключаться между разделами с
результатами и примером правильного решения, если окно содержит оба этих раздела.
Вместо щелчка на указанных маркерах достаточно нажать соответствующую клавишу:
[+], [–] или [/].
 , появляющийся в правом верхнем углу раздела с формулировкой задания
при отображении в окне полосы прокрутки. Этот маркер (и связанная с ним клавиша
[Del]) позволяет скрыть раздел с формулировкой, увеличив тем самым область окна для
отображения данных из других разделов. Заметим, что клавиша [Del] позволяет скрыть
раздел с формулировкой и в том случае, если маркер не отображается на экране.
, появляющийся в правом верхнем углу раздела с формулировкой задания
при отображении в окне полосы прокрутки. Этот маркер (и связанная с ним клавиша
[Del]) позволяет скрыть раздел с формулировкой, увеличив тем самым область окна для
отображения данных из других разделов. Заметим, что клавиша [Del] позволяет скрыть
раздел с формулировкой и в том случае, если маркер не отображается на экране.
 и
и  ,
позволяющие переключаться между несколькими
страницами раздела отладки. Напомним (см. первый рисунок), что по умолчанию в
разделе отладки выводятся строковые представления элементов исходной
последовательности. Страница раздела отладки, на которой производится вывод данных
функциями Show и ShowLine. связывается с маркером
,
позволяющие переключаться между несколькими
страницами раздела отладки. Напомним (см. первый рисунок), что по умолчанию в
разделе отладки выводятся строковые представления элементов исходной
последовательности. Страница раздела отладки, на которой производится вывод данных
функциями Show и ShowLine. связывается с маркером 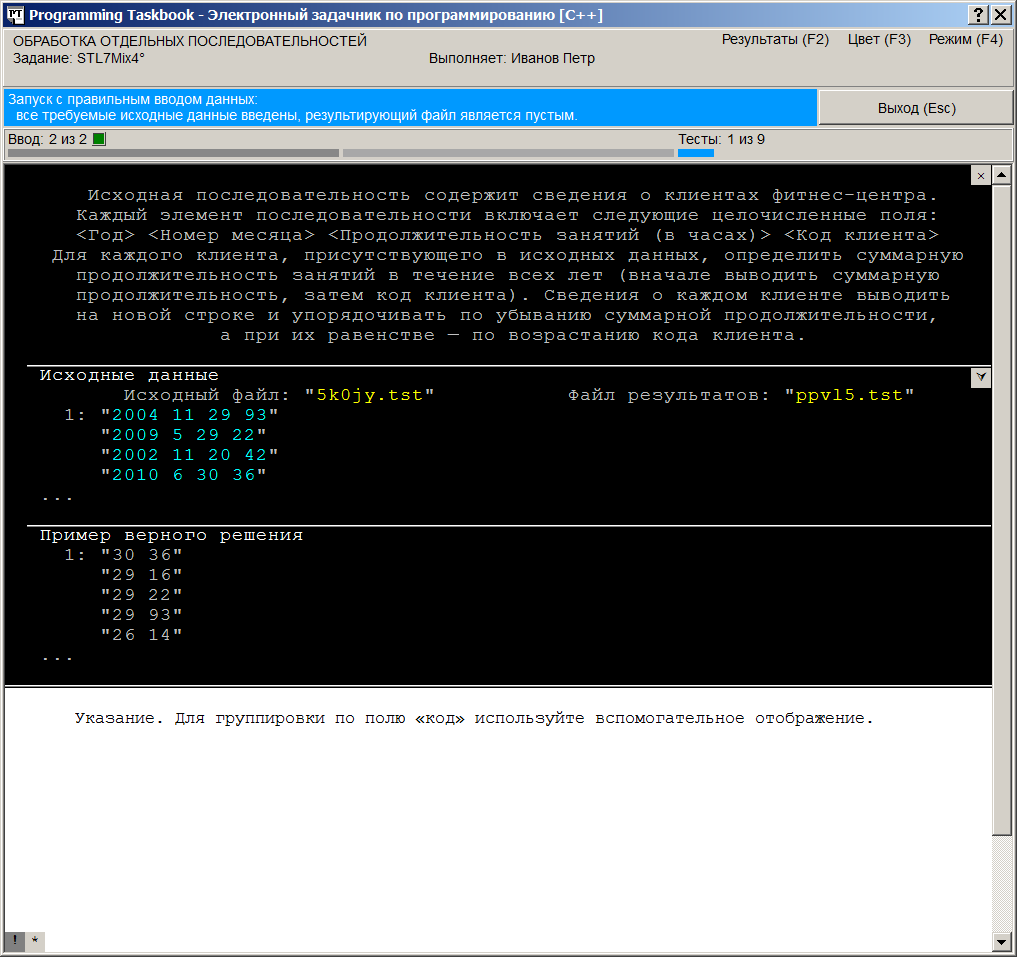
|
|
Разработка сайта: |
Последнее обновление: |