|
|
Отладка параллельных программ
Рассмотренные выше примеры выполнения заданий по
параллельному программированию показывают, что использование
задачника позволяет существенно ускорить разработку параллельных
программ. Это достигается, в первую очередь, благодаря специальному
механизму, обеспечивающему быстрый запуск параллельной программы
непосредственно из интегрированной среды. Кроме того, отладку
параллельной программы упрощает использование процедуры Show,
позволяющей вывести в раздел отладки окна задачника любые требуемые
данные из различных процессов и впоследствии просмотреть полученную
отладочную информацию как для отдельного процесса, так и для всех
процессов в целом.
Отмеченные особенности задачника могут оказаться полезными не
только при решении учебных задач по параллельному MPI-программированию,
но и при разработке параллельных программ общего назначения.
Поэтому, наряду с группой заданий MPIBegin, позволяющей ознакомиться
с большинством возможностей библиотеки MPI, в задачник Programming
Taskbook for MPI включена группа MPIDebug, предназначенная не для
выполнения определенных заданий, а для отладки любых параллельных
программ. Данная группа состоит из 36 «заданий», причем
задание с номером N обеспечивает запуск параллельной программы с N
процессами. Таким образом, если создать программу-заготовку для одного
из заданий группы MPIDebug, то при запуске этой программы из
интегрированной среды она автоматически будет выполняться в
параллельном режиме с требуемым числом процессов.
Используем группу MPIDebug для разработки программы,
реализующей один из параллельных алгоритмов умножения матрицы
A на вектор b — так называемый самопланирующий
алгоритм, в котором главный процесс
координирует работу подчиненных процессов, пересылая им требуемые
наборы данных и получая от них результаты. Исходные данные вводятся в
главном процессе. Затем главный процесс пересылает во все подчиненные
процессы вектор b и по одной из строк матрицы A. После
этого запускается цикл, в котором главный процесс принимает от
подчиненных процессов результаты умножения строки матрицы на вектор
и пересылает им оставшиеся строки матрицы A. Цикл
завершится, когда главный процесс перешлет подчиненным процессам
все строки матрицы A и получит от них все элементы
результирующего вектора Ab.
Следует заметить, что при реализации данного алгоритма нельзя
заранее определить, какие именно строки матрицы будет обрабатывать тот
или иной подчиненный процесс. Если, к примеру, программа использует
5 процессов, то строка матрицы номер 5 будет переслана тому
процессу (из числа подчиненных процессов с рангами от 1 до 4), который
первым завершит умножение ранее посланной ему строки и вернет
результат главному процессу.
Для тестирования алгоритма будем обрабатывать матрицу A
порядка N = 20, каждая строка которой содержит
одинаковые элементы, равные порядковому номеру строки:
aij = i для
i, j = 1, …, N. Вектор b того
же размера N будет содержать одинаковые элементы, равные 0.01.
Таким образом, элементы вектора c = Ab будут
иметь вид ci = 0.2i, i = 1, …,
N: с = (0.2, 0.4, 0.6, …, 3.8, 4.0).
Для правильной работы алгоритма необходимо, чтобы количество
подчиненных процессов не превосходило порядок матрицы N, так
как на начальном этапе алгоритма каждому подчиненному процессу
посылается одна из строк данной матрицы. Выберем для определенности
число процессов нашей программы равным 10; для того чтобы обеспечить
автоматический запуск параллельной программы с этим числом процессов,
будем использовать задание MPIDebug10.
При запуске программы-заготовки, созданной для этого задания, окно
задачника будет иметь следующий вид:
Вместо исходных и результирующих данных в этом окне выводится
краткое описание тех средств задачника, которые предназначены для
вывода различной отладочной информации.
Дополним созданную заготовку фрагментом, в котором описываются
необходимые переменные, выполняется формирование в главном процессе
исходной матрицы A и вектора b, а также осуществляется
пересылка вектора b во все подчиненные процессы:
[C++]
void Solve()
{
Task("MPIDebug10");
int flag;
MPI_Initialized(&flag);
if (flag == 0)
return;
int rank, size;
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
const int n = 20;
double a[n][n], b[n], c[n], d;
int cur_row;
MPI_Status s;
// генерация исходных данных в главном процессе
if (rank == 0)
for (int i = 0; i < n; ++i)
{
b[i] = 0.01;
for (int j = 0; j < n; ++j)
a[i][j] = i + 1;
}
// пересылка всем процессам вектора b
MPI_Bcast(b, n, MPI_DOUBLE, 0, MPI_COMM_WORLD);
ShowLine("Получен вектор b: ", b[n-1]);
}
[Pascal]
program MPIDebug5;
uses PT4, MPI;
const n = 20;
var
flag, size, rank: integer;
a: array [0..n-1, 0..n-1] of real;
b, c: array [0..n-1] of real;
d: real;
i, j, cur_row: integer;
s: MPI_Status;
begin
Task('MPIDebug10');
MPI_Initialized(flag);
if flag = 0 then exit;
MPI_Comm_size(MPI_COMM_WORLD, size);
MPI_Comm_rank(MPI_COMM_WORLD, rank);
// генерация исходных данных в главном процессе
if rank = 0 then
for i := 0 to n-1 do
begin
b[i] := 0.01;
for j := 0 to n-1 do
a[i, j] := i + 1;
end;
// пересылка всем процессам вектора b
MPI_Bcast(@b[0], n, MPI_DOUBLE, 0, MPI_COMM_WORLD);
ShowLine('Получен вектор b: ', b[n-1]);
end.
При запуске данного варианта программы в окне задачника появится
раздел отладки:
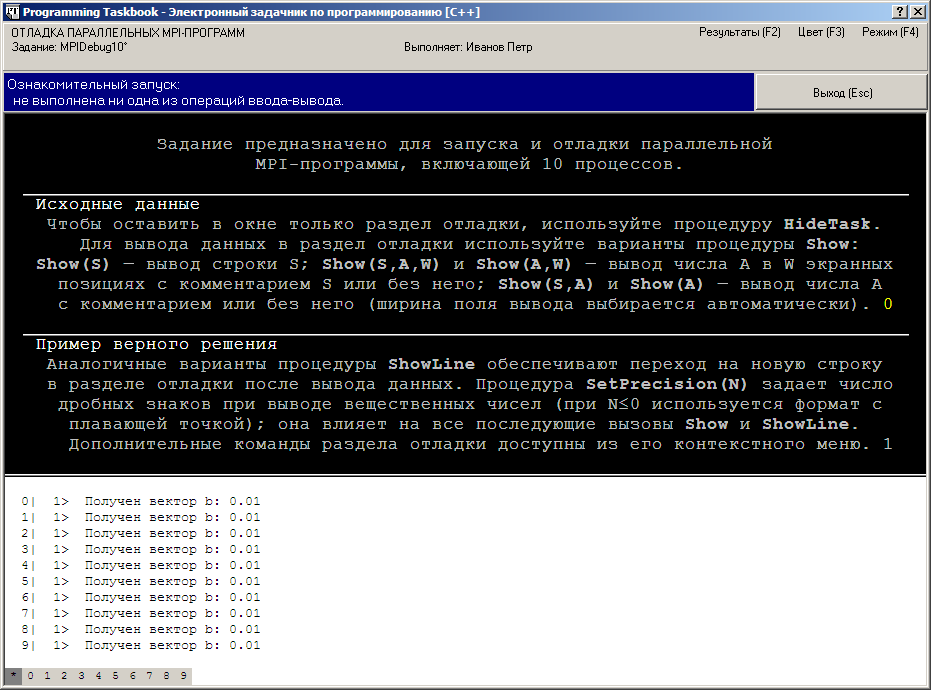
Поскольку в программе используются вызовы процедуры Show (или
ShowLine), в окне задачника автоматически отображается раздел отладки с
информацией, которая была выведена с помощью этих процедур. В нашем
случае каждый из процессов (включая главный) вывел информацию о том,
что он успешно получил вектор b (для краткости выведено только
значение последнего элемента массива b с индексом
n – 1).
Так как в основных разделах окна задачника в нашем случае
содержится лишь справочная информация, удобно скрыть все разделы
окна, кроме раздела отладки. Если мы уже находимся в окне задачника, то
для этого достаточно нажать клавишу пробела. Однако еще удобнее
автоматически скрывать ненужные разделы при выводе окна задачника на
экран. Для этого достаточно вызвать в любом месте программы
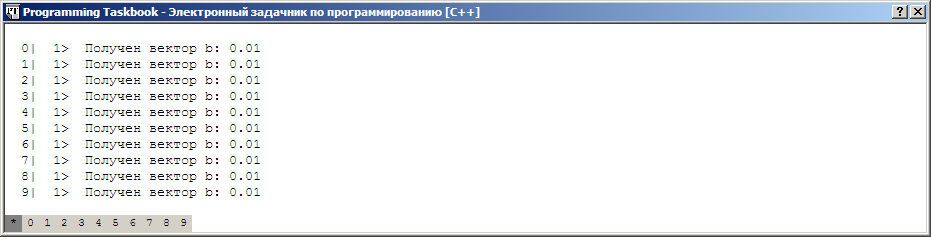
вспомогательную процедуру HideTask. Если добавить вызов этой
процедуры в конец нашей программы и повторно запустить ее на
выполнение, то окно задачника будет содержать только раздел отладки:
Вернемся к реализации алгоритма умножения матрицы на вектор и
приведем его завершающую часть:
[C++]
if (rank == 0)
{
// пересылка подчиненным процессам начальных строк матрицы A
for (int i = 1; i < size; ++i)
{
MPI_Send(a[i-1], n, MPI_DOUBLE, i, i-1, MPI_COMM_WORLD);
Show("Отправлены начальные данные, dest = ", i);
ShowLine(": ", a[i-1][0]);
}
cur_row = size - 2;
// получение элементов произведения и пересылка оставшихся строк
for (int i = 0; i < n; ++i)
{
MPI_Recv(&d, 1, MPI_DOUBLE, MPI_ANY_SOURCE, MPI_ANY_TAG,
MPI_COMM_WORLD, &s);
Show("Получены результаты, tag = ", s.MPI_TAG, 2);
Show("source = ", s.MPI_SOURCE);
Show(": ", d);
c[s.MPI_TAG] = d;
++cur_row;
if (cur_row < n)
MPI_Send(a[cur_row], n, MPI_DOUBLE, s.MPI_SOURCE,
cur_row, MPI_COMM_WORLD);
else
MPI_Send(&d, 1, MPI_DOUBLE, s.MPI_SOURCE, n,
MPI_COMM_WORLD);
ShowLine("| Отправлены данные, dest = ", s.MPI_SOURCE);
}
SetPrecision(1);
for (int i = 0; i < n; ++i)
Show(c[i], 3);
}
else
// обработка данных в подчиненных процессах
while (TRUE)
{
MPI_Recv(c, n, MPI_DOUBLE, 0, MPI_ANY_TAG, MPI_COMM_WORLD,
&s);
Show("Получены данные, tag = ", s.MPI_TAG, 2);
if (s.MPI_TAG >= n)
break;
d = 0;
for (int i = 0; i < n; ++i)
d += c[i] * b[i];
MPI_Send(&d, 1, MPI_DOUBLE, 0, s.MPI_TAG,
MPI_COMM_WORLD);
Show("| Отправлены результаты, tag = ", s.MPI_TAG,2);
ShowLine(": ", d);
}
[Pascal]
if rank = 0 then
begin
// пересылка подчиненным процессам начальных строк матрицы A
for i := 1 to size-1 do
begin
MPI_Send(@a[i-1, 0], n, MPI_DOUBLE, i, i-1, MPI_COMM_WORLD);
Show('Отправлены начальные данные, dest = ', i);
ShowLine(': ', a[i-1, 0]);
end;
cur_row := size - 2;
// получение элементов произведения и пересылка оставшихся строк
for i := 0 to n-1 do
begin
MPI_Recv(@d, 1, MPI_DOUBLE, MPI_ANY_SOURCE, MPI_ANY_TAG,
MPI_COMM_WORLD, s);
Show('Получены результаты, tag = ', s.MPI_TAG, 2);
Show('source = ', s.MPI_SOURCE);
Show(': ', d);
c[s.MPI_TAG] := d;
Inc(cur_row);
if cur_row < n then
MPI_Send(@a[cur_row, 0], n, MPI_DOUBLE, s.MPI_SOURCE,
cur_row, MPI_COMM_WORLD)
else
MPI_Send(@d, 1, MPI_DOUBLE, s.MPI_SOURCE, n,
MPI_COMM_WORLD);
ShowLine('| Отправлены данные, dest = ', s.MPI_SOURCE);
end;
SetPrecision(1);
for i := 0 to n-1 do
Show(c[i], 3);
end
else
// обработка данных в подчиненных процессах
while true do
begin
MPI_Recv(@c[0], n, MPI_DOUBLE, 0, MPI_ANY_TAG,
MPI_COMM_WORLD, s);
Show('Получены данные, tag = ', s.MPI_TAG, 2);
if s.MPI_TAG = n then
break;
d := 0;
for i := 0 to n-1 do
d := d + c[i] * b[i];
MPI_Send(@d, 1, MPI_DOUBLE, 0, s.MPI_TAG,
MPI_COMM_WORLD);
Show('| Отправлены результаты, tag = ', s.MPI_TAG, 2);
ShowLine(': ', d);
end;
Данная часть состоит из двух больших фрагментов, первый из
которых должен выполняться в главном процессе, а второй — в
каждом из подчиненных процессов.
Главный процесс вначале пересылает каждому подчиненному
процессу по одной из строк исходной матрицы и инициализирует
переменную cur_row, в которой содержится индекс последней
обработанной, т. е. пересланной в подчиненный процесс, строки
матрицы (строки индексируются от нуля). После этого запускается
основной цикл, в котором главный процесс получает от подчиненных
процессов результирующие элементы произведения и пересылает им
очередные строки матрицы. Поскольку порядок получения данных от
подчиненных процессов не определен, в функции MPI_Recv используется
параметр MPI_ANY_SOURCE, обеспечивающий получение данных от
любого пославшего их процесса. В метке сообщения (tag)
подчиненный процесс передает главному процессу дополнительную
информацию — индекс вычисленного элемента произведения. Для
того чтобы главный процесс мог принимать сообщения с любыми
метками, параметр msgtag функции MPI_Recv полагается равным
MPI_ANY_TAG. Информацию о ранге процесса, пославшего сообщение, и
о метке сообщения главный процесс получает с помощью записи s типа
MPI_Status, обращаясь к ее полям MPI_SOURCE и MPI_TAG
соответственно. После получения сообщения от подчиненного процесса
главный процесс отправляет ему новое сообщение, которое либо содержит
очередную необработанную строку матрицы (если такие строки еще
остались), либо специальный признак завершения. Если посылается
очередная строка, то метка посылаемого сообщения полагается равной
индексу строки cur_row; если же посылается признак завершения, то метка
содержит число n, т. е. величину, которая на 1 больше
максимального индекса строки матрицы. После завершения цикла for в
главном процессе выводятся все элементы найденного произведения.
В подчиненном процессе запускается цикл, в котором вначале
выполняется прием очередной строки матрицы из главного процесса (ее
индекс передается в метке сообщения), затем полученная строка
умножается на ранее полученный вектор, и наконец, результат умножения
пересылается главному процессу. Если же при приеме очередного
сообщения от главного процесса будет получена метка, превышающая
номер максимального индекса строки матрицы, то происходит
немедленный выход из цикла, и подчиненный процесс завершает свою
работу.
Все этапы описанного выше алгоритма сопровождаются отладочной
печатью. Для этого используется процедура Show и ее вариант ShowLine
(обеспечивающий дополнительный переход на новую строку в разделе
отладки после вывода данных). Перед выводом
очередного числового элемента, как правило, выводится предваряющий его строковый
комментарий, а в некоторых случаях после числового элемента
дополнительно указывается количество экранных позиций, которые
следует отвести для его вывода (это позволяет обеспечить выравнивание
выводимых данных по вертикали). Перед выводом в главном процессе
элементов результирующего произведения вызывается процедура
SetPrecision(1), обеспечивающая вывод всех последующих данных
вещественного типа с одним знаком после десятичного разделителя
(заметим, что по умолчанию число дробных знаков полагается равным 2,
однако при использовании этого значения все результирующие элементы
не удалось бы вывести в одной строке, так как ширина области выводимых
данных в разделе отладки фиксирована и равна 80 позициям).
При оформлении вывода было учтено, что данные, выводимые
процедурой Show или ShowLine, отделяются одним пробелом от ранее
выведенных данных, находящихся на той же экранной строке.
Приведем отладочные данные, которые были получены при запуске
программы (напомним, что перед первым символом «|» указывается ранг
процесса, который вывел соответствующую строку отладочной
информации, а перед символом «>» — порядковый
номер выведенной строки; при этом строки, связанные с различными процессами,
нумеруются независимо):
0| 1> Получен вектор b: 0.01
0| 2> Отправлены начальные данные, dest = 1 : 1.00
0| 3> Отправлены начальные данные, dest = 2 : 2.00
0| 4> Отправлены начальные данные, dest = 3 : 3.00
0| 5> Отправлены начальные данные, dest = 4 : 4.00
0| 6> Отправлены начальные данные, dest = 5 : 5.00
0| 7> Отправлены начальные данные, dest = 6 : 6.00
0| 8> Отправлены начальные данные, dest = 7 : 7.00
0| 9> Отправлены начальные данные, dest = 8 : 8.00
0| 10> Отправлены начальные данные, dest = 9 : 9.00
0| 11> Получены результаты, tag = 7 source = 8 : 1.60 | Отправлены данные, dest = 8
0| 12> Получены результаты, tag = 3 source = 4 : 0.80 | Отправлены данные, dest = 4
0| 13> Получены результаты, tag = 9 source = 8 : 2.00 | Отправлены данные, dest = 8
0| 14> Получены результаты, tag = 1 source = 2 : 0.40 | Отправлены данные, dest = 2
0| 15> Получены результаты, tag = 0 source = 1 : 0.20 | Отправлены данные, dest = 1
0| 16> Получены результаты, tag = 2 source = 3 : 0.60 | Отправлены данные, dest = 3
0| 17> Получены результаты, tag = 4 source = 5 : 1.00 | Отправлены данные, dest = 5
0| 18> Получены результаты, tag = 5 source = 6 : 1.20 | Отправлены данные, dest = 6
0| 19> Получены результаты, tag = 6 source = 7 : 1.40 | Отправлены данные, dest = 7
0| 20> Получены результаты, tag = 8 source = 9 : 1.80 | Отправлены данные, dest = 9
0| 21> Получены результаты, tag = 10 source = 4 : 2.20 | Отправлены данные, dest = 4
0| 22> Получены результаты, tag = 11 source = 8 : 2.40 | Отправлены данные, dest = 8
0| 23> Получены результаты, tag = 13 source = 1 : 2.80 | Отправлены данные, dest = 1
0| 24> Получены результаты, tag = 14 source = 3 : 3.00 | Отправлены данные, dest = 3
0| 25> Получены результаты, tag = 12 source = 2 : 2.60 | Отправлены данные, dest = 2
0| 26> Получены результаты, tag = 15 source = 5 : 3.20 | Отправлены данные, dest = 5
0| 27> Получены результаты, tag = 16 source = 6 : 3.40 | Отправлены данные, dest = 6
0| 28> Получены результаты, tag = 17 source = 7 : 3.60 | Отправлены данные, dest = 7
0| 29> Получены результаты, tag = 19 source = 4 : 4.00 | Отправлены данные, dest = 4
0| 30> Получены результаты, tag = 18 source = 9 : 3.80 | Отправлены данные, dest = 9
0| 31> 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 3.6 3.8 4.0
1| 1> Получен вектор b: 0.01
1| 2> Получены данные, tag = 0 | Отправлены результаты, tag = 0 : 0.20
1| 3> Получены данные, tag = 13 | Отправлены результаты, tag = 13 : 2.80
1| 4> Получены данные, tag = 20
2| 1> Получен вектор b: 0.01
2| 2> Получены данные, tag = 1 | Отправлены результаты, tag = 1 : 0.40
2| 3> Получены данные, tag = 12 | Отправлены результаты, tag = 12 : 2.60
2| 4> Получены данные, tag = 20
3| 1> Получен вектор b: 0.01
3| 2> Получены данные, tag = 2 | Отправлены результаты, tag = 2 : 0.60
3| 3> Получены данные, tag = 14 | Отправлены результаты, tag = 14 : 3.00
3| 4> Получены данные, tag = 20
4| 1> Получен вектор b: 0.01
4| 2> Получены данные, tag = 3 | Отправлены результаты, tag = 3 : 0.80
4| 3> Получены данные, tag = 10 | Отправлены результаты, tag = 10 : 2.20
4| 4> Получены данные, tag = 19 | Отправлены результаты, tag = 19 : 4.00
4| 5> Получены данные, tag = 20
5| 1> Получен вектор b: 0.01
5| 2> Получены данные, tag = 4 | Отправлены результаты, tag = 4 : 1.00
5| 3> Получены данные, tag = 15 | Отправлены результаты, tag = 15 : 3.20
5| 4> Получены данные, tag = 20
6| 1> Получен вектор b: 0.01
6| 2> Получены данные, tag = 5 | Отправлены результаты, tag = 5 : 1.20
6| 3> Получены данные, tag = 16 | Отправлены результаты, tag = 16 : 3.40
6| 4> Получены данные, tag = 20
7| 1> Получен вектор b: 0.01
7| 2> Получены данные, tag = 6 | Отправлены результаты, tag = 6 : 1.40
7| 3> Получены данные, tag = 17 | Отправлены результаты, tag = 17 : 3.60
7| 4> Получены данные, tag = 20
8| 1> Получен вектор b: 0.01
8| 2> Получены данные, tag = 7 | Отправлены результаты, tag = 7 : 1.60
8| 3> Получены данные, tag = 9 | Отправлены результаты, tag = 9 : 2.00
8| 4> Получены данные, tag = 11 | Отправлены результаты, tag = 11 : 2.40
8| 5> Получены данные, tag = 20
9| 1> Получен вектор b: 0.01
9| 2> Получены данные, tag = 8 | Отправлены результаты, tag = 8 : 1.80
9| 3> Получены данные, tag = 18 | Отправлены результаты, tag = 18 : 3.80
9| 4> Получены данные, tag = 20
Из приведенного текста видно, что в ходе выполнения алгоритма
процессы рангов 4 и 8 обработали по 3 строки исходной матрицы, а
остальные 7 подчиненных процессов — по 2 строки. В последней, 31-й
строке, связанной с главным процессом, содержатся элементы
найденного произведения.
Заметим, что текст, который отображается в разделе отладки окна
задачника, можно скопировать в буфер обмена Windows; для этого
достаточно либо нажать стандартную комбинацию клавиш [Ctrl]+[C], либо
вызвать контекстное меню раздела отладки (нажав правую кнопку мыши)
и выполнить его команду «Скопировать данные из окна отладки в
буфер».
Изменив имя задания в процедуре Task на «MPIDebug5»,
мы сможем протестировать разработанный алгоритм в параллельном
режиме, использующем 5 процессов. Приведем отладочную информацию,
которая была выведена при таком варианте запуска программы:
0| 1> Получен вектор b: 0.01
0| 2> Отправлены начальные данные, dest = 1 : 1.00
0| 3> Отправлены начальные данные, dest = 2 : 2.00
0| 4> Отправлены начальные данные, dest = 3 : 3.00
0| 5> Отправлены начальные данные, dest = 4 : 4.00
0| 6> Получены результаты, tag = 1 source = 2 : 0.40 | Отправлены данные, dest = 2
0| 7> Получены результаты, tag = 0 source = 1 : 0.20 | Отправлены данные, dest = 1
0| 8> Получены результаты, tag = 3 source = 4 : 0.80 | Отправлены данные, dest = 4
0| 9> Получены результаты, tag = 4 source = 2 : 1.00 | Отправлены данные, dest = 2
0| 10> Получены результаты, tag = 2 source = 3 : 0.60 | Отправлены данные, dest = 3
0| 11> Получены результаты, tag = 5 source = 1 : 1.20 | Отправлены данные, dest = 1
0| 12> Получены результаты, tag = 6 source = 4 : 1.40 | Отправлены данные, dest = 4
0| 13> Получены результаты, tag = 7 source = 2 : 1.60 | Отправлены данные, dest = 2
0| 14> Получены результаты, tag = 8 source = 3 : 1.80 | Отправлены данные, dest = 3
0| 15> Получены результаты, tag = 9 source = 1 : 2.00 | Отправлены данные, dest = 1
0| 16> Получены результаты, tag = 10 source = 4 : 2.20 | Отправлены данные, dest = 4
0| 17> Получены результаты, tag = 11 source = 2 : 2.40 | Отправлены данные, dest = 2
0| 18> Получены результаты, tag = 12 source = 3 : 2.60 | Отправлены данные, dest = 3
0| 19> Получены результаты, tag = 13 source = 1 : 2.80 | Отправлены данные, dest = 1
0| 20> Получены результаты, tag = 14 source = 4 : 3.00 | Отправлены данные, dest = 4
0| 21> Получены результаты, tag = 16 source = 3 : 3.40 | Отправлены данные, dest = 3
0| 22> Получены результаты, tag = 15 source = 2 : 3.20 | Отправлены данные, dest = 2
0| 23> Получены результаты, tag = 17 source = 1 : 3.60 | Отправлены данные, dest = 1
0| 24> Получены результаты, tag = 18 source = 4 : 3.80 | Отправлены данные, dest = 4
0| 25> Получены результаты, tag = 19 source = 3 : 4.00 | Отправлены данные, dest = 3
0| 26> 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 3.6 3.8 4.0
1| 1> Получен вектор b: 0.01
1| 2> Получены данные, tag = 0 | Отправлены результаты, tag = 0 : 0.20
1| 3> Получены данные, tag = 5 | Отправлены результаты, tag = 5 : 1.20
1| 4> Получены данные, tag = 9 | Отправлены результаты, tag = 9 : 2.00
1| 5> Получены данные, tag = 13 | Отправлены результаты, tag = 13 : 2.80
1| 6> Получены данные, tag = 17 | Отправлены результаты, tag = 17 : 3.60
1| 7> Получены данные, tag = 20
2| 1> Получен вектор b: 0.01
2| 2> Получены данные, tag = 1 | Отправлены результаты, tag = 1 : 0.40
2| 3> Получены данные, tag = 4 | Отправлены результаты, tag = 4 : 1.00
2| 4> Получены данные, tag = 7 | Отправлены результаты, tag = 7 : 1.60
2| 5> Получены данные, tag = 11 | Отправлены результаты, tag = 11 : 2.40
2| 6> Получены данные, tag = 15 | Отправлены результаты, tag = 15 : 3.20
2| 7> Получены данные, tag = 20
3| 1> Получен вектор b: 0.01
3| 2> Получены данные, tag = 2 | Отправлены результаты, tag = 2 : 0.60
3| 3> Получены данные, tag = 8 | Отправлены результаты, tag = 8 : 1.80
3| 4> Получены данные, tag = 12 | Отправлены результаты, tag = 12 : 2.60
3| 5> Получены данные, tag = 16 | Отправлены результаты, tag = 16 : 3.40
3| 6> Получены данные, tag = 19 | Отправлены результаты, tag = 19 : 4.00
3| 7> Получены данные, tag = 20
4| 1> Получен вектор b: 0.01
4| 2> Получены данные, tag = 3 | Отправлены результаты, tag = 3 : 0.80
4| 3> Получены данные, tag = 6 | Отправлены результаты, tag = 6 : 1.40
4| 4> Получены данные, tag = 10 | Отправлены результаты, tag = 10 : 2.20
4| 5> Получены данные, tag = 14 | Отправлены результаты, tag = 14 : 3.00
4| 6> Получены данные, tag = 18 | Отправлены результаты, tag = 18 : 3.80
4| 7> Получены данные, tag = 20
|

