|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
Разработка и запуск параллельных программ без использования электронного задачникаПример, приведенный в предыдущем разделе, наглядно продемонстрировал, что применение средств электронного задачника Programming Taskbook for MPI-2 позволяет существенно ускорить разработку параллельных программ. Однако нашей конечной целью является все же создание параллельных программ, выполнение которых не зависит от наличия на компьютере электронного задачника. В данном пункте мы подробно опишем процесс создания таких программ в среде Microsoft Visual Studio. Аналогичным образом параллельные программы можно разрабатывать и в других средах на локальном компьютере (например, в среде Code::Blocks). Разумеется, параллельные программы обычно предназначаются для запуска на суперкомпьютере или вычислительном кластере, однако при наличии параллельной программы, созданной и протестированной на локальном компьютере, перенос ее на другую вычислительную платформу потребует лишь знаний о том, как выполнять компиляцию и запуск программы на этой платформе. Для определенности будем считать, что программа разрабатывается в среде Microsoft Visual Studio 2015. Создайте в этой среде новое консольное приложение, выполнив для этого следующие стандартные действия:
В результате проект ParallelApplication1 будет создан, и в редактор кода загрузится главный файл этого проекта ParallelApplication1.cpp со следующим содержимым: #include "stdafx.h"
int main()
{
return 0;
}
В других версиях Visual Studio имя стартовой функции и ее параметры могут быть другими. Например, файл, созданный в Visual Studio 2008, будет содержать следующий текст: #include "stdafx.h"
int _tmain(int argc, _TCHAR* argv[])
{
return 0;
}
Откорректируйте файл ParallelApplication1.cpp, удалив ненужную директиву #include и указав стандартное имя и параметры для стартовой функции: int main(int argc, char* argv[])
{
return 0;
}
Полученная программа должна успешно компилироваться. При ее запуске на экране на долю секунды будет возникать консольное окно. Теперь добавим к проекту следующие компоненты, позволяющие использовать библиотеку MPI (проще всего скопировать все эти компоненты из рабочего каталога PT4Work в каталог проекта, т. е. в каталог, в котором уже содержится файл ParallelApplication1.cpp):
Эти файлы можно также скопировать из каталога системы MPICH2: заголовочные файлы содержатся в подкаталоге include, а lib-файл — в подкаталоге lib и имеет имя mpi.lib (ранее уже отмечалось, что имя lib-файла в задачнике было изменено на mpich.lib для согласования с именем lib-файла системы MPICH 1.2.5). В дальнейшем будем считать, что lib-файл имеет имя mpich.lib. Необходимо подключить lib-файл к проекту (требуемые для этого действия уже описывались ранее — см. примечание 2 в разделе «Создание заготовки»: надо начать с команды меню команду меню«Project | <имя проекта> Properties…», перейти в появившемся окне свойств проекта в раздел «Configuration Properties | Linker | Input» и указать имя подключаемого файла mpich.lib в поле ввода «Additional Dependencies», отделив его от последующих имен точкой с запятой). Выполнять особые действия по подключению к проекту заголовочных файлов не требуется. Добавим в главный файл проекта директивы подключения необходимых заголовочных файлов и включим в функцию main операторы, обеспечивающие инициализацию параллельного режима, печать ранга процесса и завершение параллельного режима (добавленный текст выделен полужирным шрифтом): #include <iostream>
#include "mpi.h"
int main(int argc, char* argv[])
{
MPI_Init(&argc, &argv);
int rank;
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
std::cout << rank << '\n';
MPI_Finalize();
return 0;
}
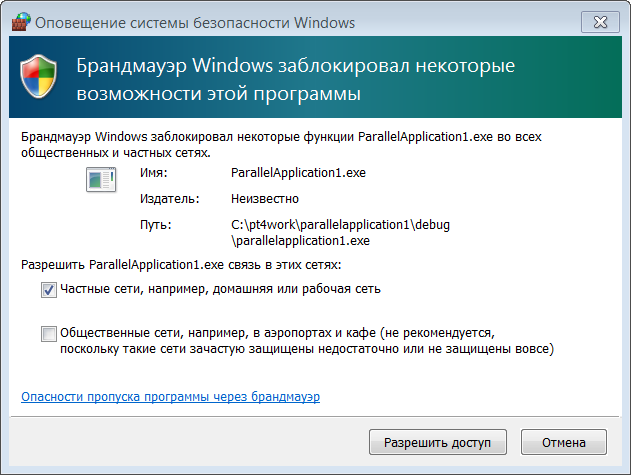
Обратите внимание на то, что здесь мы впервые использовали функции MPI_Init и MPI_Finalize (во всех предыдущих программах эти функции вызывались самим задачником). Если все действия по подключению компонентов MPI были выполнены правильно, то данная программа успешно откомпилируется и запустится на выполнение. При ее первом запуске на экране появится окно системы безопасности Windows, в котором надо нажать кнопку «Разрешить доступ»:
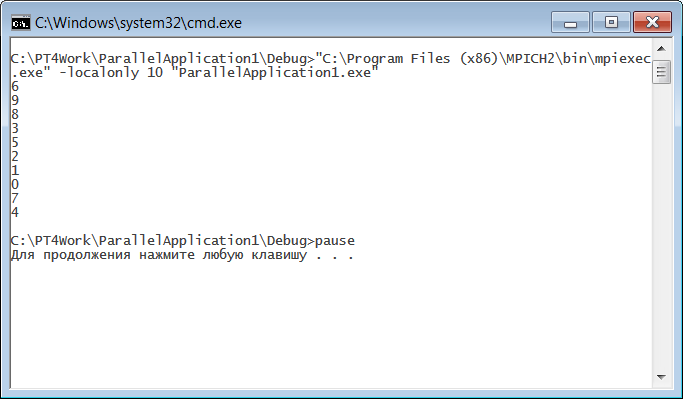
Теперь необходимо подготовить пакетный файл, обеспечивающий запуск полученный программы в параллельном режиме. Назовем этот файл mpi_run.bat и сохраним его в том же каталоге, в котором хранится исполняемый файл ParallelApplication1.exe (это позволит нам не указывать полный путь к этому файлу). Файл должен содержать две команды, каждая команда должна располагаться на одной строке: "C:\Program Files (x86)\MPICH2\bin\mpiexec.exe" -localonly 10 "ParallelApplication1.exe" pause После запуска этого файла на экране появится консольное окно с результатом работы нашей программы в параллельном режиме:
Мы видим, что каждый процесс действительно вывел в консольном окне свой ранг. При этом порядок вывода данных из различных процессов является недетерминированным: при каждом запуске программы мы будем получать другую последовательность чисел в диапазоне от 0 до 9. Итак, мы, наконец, разработали параллельную программу, которая может компилироваться и запускаться на выполнение независимо от электронного задачника. Правда, эта программа является очень простой. Примечание. При разработке параллельных программ в среде Microsoft Visual Studio можно обойтись без вспомогательного bat-файла, если указать управляющую программу mpiexec.exe и ее параметры в настройках проекта (см. примечание 1 в разделе «Запуск программы», а также раздел «Примеры», в котором механизм управляющих программ используется для тестирования библиотеки с новой группой заданий). При этом, однако, потребуется добавить в программу фрагмент, обеспечивающий ее приостановку в конце выполнения. В предыдущем разделе мы разработали достаточно сложную параллельную программу, реализующую самопланирующий алгоритм умножения матрицы на вектор. При ее разработке и отладке нам помогли возможности задачника, однако теперь мы хотим запустить ее независимо от задачника. Оказывается, сделать это достаточно просто. Прежде всего, включим в наше консольное приложение файл MPIDebug10.cpp, в котором содержится текст ранее разработанной программы. Для этого скопируем его из каталога PT4Work в каталог консольного приложения (содержащий файл ParallelApplication1.cpp) и выполним команду меню «Project | Add Existing Item…», выбрав в появившемся окне файл MPIDebug10.cpp. Загрузим файл MPIDebug10.cpp в редактор кода. В настоящий момент он имеет следующий вид (содержимое функции Solve для краткости опускаем): #include "pt4.h"
#include "mpi.h"
void Solve()
{
. . .
}
При этом функция Solve содержит большое количество вызовов
функций, связанных с задачником и взятых из заголовочного файла pt4.h.
Разумеется, можно просто удалить директиву подключения файла pt4.h, а
также удалить (или закомментировать) все подобные вызовы. Однако в
задачнике предусмотрена более удобная возможность: заглушка (англ. stub)
для заголовочного файла pt4.h. Простейший вариант такой заглушки
оформлен в виде файла pt4null.h и содержит «пустые» реализации всех
функций, связанных с задачником. Таким образом, можно, не меняя
содержимое функции Solve, просто заменить директиву #include "pt4null.h"
#include "mpi.h"
void Solve()
{
. . .
}
Необходимо также скопировать файл-заглушку pt4null.h в каталог проекта. Данный файл содержится в каталоге PTforMPI2\stubs системного каталога задачника Programming Taskbook (по умолчанию это каталог PT4, расположенный в каталоге Program Files для 32-разрядных программ — c:\Program Files (x86)). Выполнив указанные действия, мы обнаружим, что все подчеркивания, связанные с обнаруженными ошибками, в файле MPIDebug10.cpp исчезли. Правда, мы при этом потеряли все возможности нашей программы, связанные с выводом данных на экран. Мы не будем пытаться (пока) восстановить всю отладочную
информацию, которая выводилась в функции Solve, ограничившись
печатью элементов итогового произведения — вектора Ab. Для этого
добавим с начало файла MPIDebug10.cpp директиву for (int i = 0; i < n; ++i) std::cout << c[i] << ' '; std::cout << '\n'; Нам осталось откорректировать содержимое главного файла таким образом, чтобы в нем вместо печати рангов процессов выполнялся вызов функции Solve (добавленные или измененные фрагменты выделены полужирным шрифтом): #include <iostream>
#include "mpi.h"
void Solve();
int main(int argc, char* argv[])
{
MPI_Init(&argc, &argv);
Solve();
MPI_Finalize();
return 0;
}
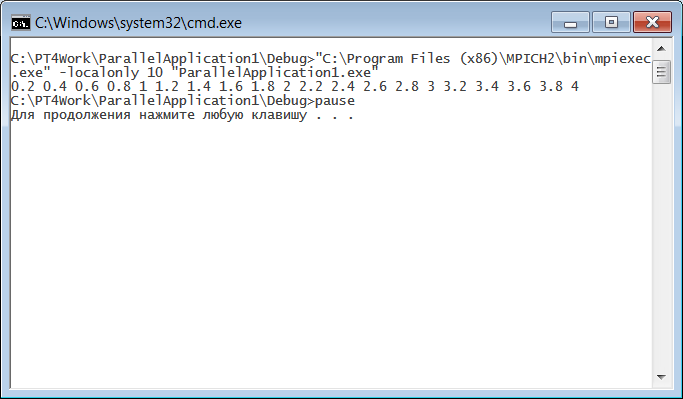
Теперь осталось откомпилировать и собрать полученный вариант программы (выполнив команду «Build | Build solution» или нажав комбинацию клавиш Ctrl+Shift+B) и, убедившись, что компиляция и сборка выполнены успешно, запустить файл mpi_run.bat (в котором не требуется вносить никаких изменений). Результат работы данного файла приведен на рисунке:
Мы видим, что найденные элементы вектора Ab совпадают с теми, которые были получены в программе из предыдущего раздела. В задачнике PT for MPI-2 предусмотрен еще один вариант заглушки для файла pt4.h, который позволяет использовать в «обычной» консольной параллельной программе все возможности по отладочному выводу, предусмотренные в задачнике. Этот вариант заглушки имеет имя pt4console и состоит из двух файлов: pt4console.cpp и pt4console.h. Продемонстрируем его применение. Прежде всего, скопируем файлы pt4console.cpp и pt4console.h из каталога задачника в каталог консольного приложения (эти файлы располагаются в каталоге задачника там же, где и файл pt4null.h). Затем подключим к консольному приложению файл pt4console.cpp, выполнив для него команду меню «Project | Add Existing Item…». После этого в файле MPIDebug10.cpp заменим директиву #pragma hdrstop
#include "pt4console.h"
#include "mpi.h"
void Solve()
{
. . .
ShowAll();
}
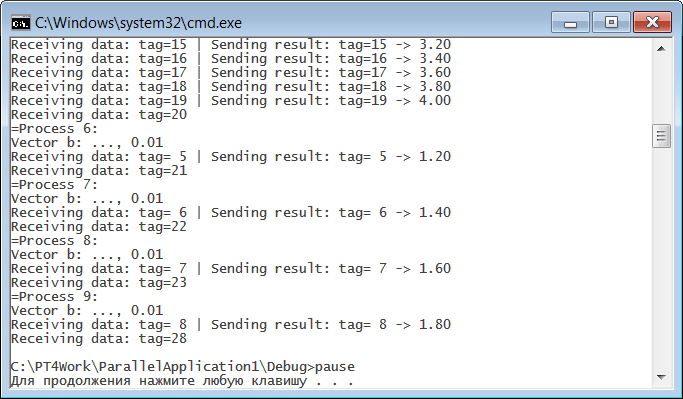
Обратите внимание на то, что функция ShowAll является коллективной и должна вызываться для всех процессов параллельного приложения. Можно также удалить ранее добавленный в функцию Solve фрагмент, обеспечивающий вывод вектора Ab в консольное окно, но это делать необязательно. Файл ParallelApplication1.cpp корректировать не требуется. Откомпилировав и собрав новый вариант программы командой «Build | Build solution» и запустив файл mpi_run.bat, мы получим в консольном окне ту же информацию, которая ранее (в программе из в предыдущего пункта) отображалась в разделе отладки окна задачника:
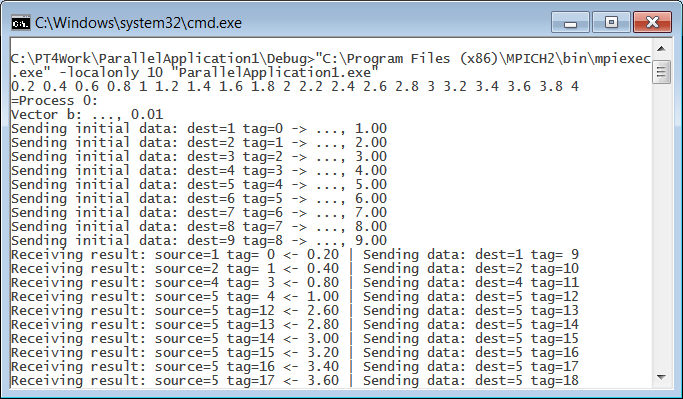
Отличие состоит лишь в том, что строки вывода не нумеруются, а ранг процесса указывается в специальной строке, начинающейся со знака равенства «=». Подчеркнем, что данный вариант вывода является детерминированным: все данные группируются по процессам, в которых они выведены, а процессы перебираются по возрастанию их рангов. Если пролистать содержимое консольного окна к началу, то можно убедиться в том, что в главном процессе вначале был выведен полученный вектор Ab, а затем начался вывод данных, собранных из функций Show:
Читателю рекомендуется проанализировать содержимое файла pt4console.cpp (и прежде всего функции ShowAll), чтобы выяснить, каким образом удалось организовать подобный вывод данных. Вывод на консоль в функции ShowAll выполняет только главный процесс, именно поэтому этот вывод является полностью детерминированным. Предварительно в этой функции главный процесс собирает от подчиненных процессов все данные, которые были получены в них с помощью функций Show и ShowLine, после чего выводит их на консоль в требуемом порядке (подчиненные процессы в этой же функции организуют пересылку своих данных главному процессу). Завершая обзор примеров, связанных с разработкой параллельных программ без подключения к ним задачника, отметим еще одну полезную возможность. Часто бывает желательно организовать вывод данных таким образом, чтобы он сохранился после завершения программы. Обычно для этого выполняется сохранение результатов в некотором файле. Для консольных приложений подобное сохранение можно выполнить очень легко, используя перенаправление потока вывода. В случае нашей программы следует лишь немного дополнить первую команду из файла mpi_run.bat (добавленный фрагмент выделен полужирным шрифтом): "C:\Program Files (x86)\MPICH2\bin\mpiexec.exe" -localonly 10
"ParallelApplication1.exe" > results.txt
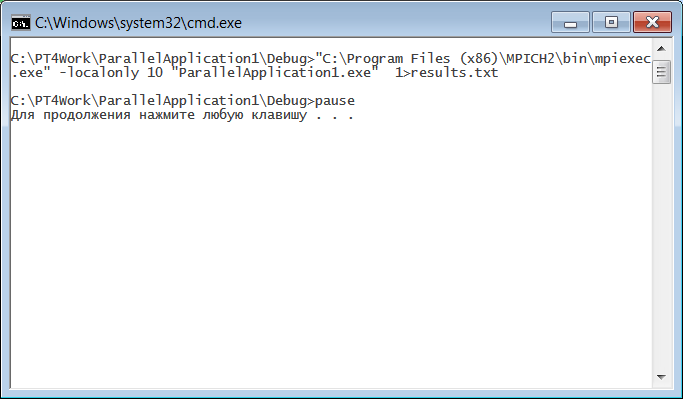
Символ «>» означает, что поток вывода при выполнении данной команды будет перенаправлен из консольного окна в файл, имя которого указано после данного символа (мы выбрали имя results.txt). Если такого файла нет, то он создается, если он уже есть, то его содержимое перезаписывается. При запуске измененного файла mpi-run.bat консольное окно не будет содержать никаких выведенных данных:
В подобной ситуации целесообразно удалить из bat-файла команду pause, поскольку содержимое консольного окна теперь просматривать не требуется. Однако теперь на диске в том же каталоге появится файл results.txt, содержащий все данные, выведенные нашей программой. Приведем вариант содержимого данного файла (сравните его с вариантами, приведенными в конце предыдущего раздела): 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 2.2 2.4 2.6 2.8 3 3.2 3.4 3.6 3.8 4 =Process 0: Vector b: ..., 0.01 Sending initial data: dest=1 tag=0 -> ..., 1.00 Sending initial data: dest=2 tag=1 -> ..., 2.00 Sending initial data: dest=3 tag=2 -> ..., 3.00 Sending initial data: dest=4 tag=3 -> ..., 4.00 Sending initial data: dest=5 tag=4 -> ..., 5.00 Sending initial data: dest=6 tag=5 -> ..., 6.00 Sending initial data: dest=7 tag=6 -> ..., 7.00 Sending initial data: dest=8 tag=7 -> ..., 8.00 Sending initial data: dest=9 tag=8 -> ..., 9.00 Receiving result: source=1 tag= 0 <- 0.20 | Sending data: dest=1 tag= 9 Receiving result: source=2 tag= 1 <- 0.40 | Sending data: dest=2 tag=10 Receiving result: source=4 tag= 3 <- 0.80 | Sending data: dest=4 tag=11 Receiving result: source=5 tag= 4 <- 1.00 | Sending data: dest=5 tag=12 Receiving result: source=6 tag= 5 <- 1.20 | Sending data: dest=6 tag=13 Receiving result: source=7 tag= 6 <- 1.40 | Sending data: dest=7 tag=14 Receiving result: source=7 tag=14 <- 3.00 | Sending data: dest=7 tag=15 Receiving result: source=7 tag=15 <- 3.20 | Sending data: dest=7 tag=16 Receiving result: source=7 tag=16 <- 3.40 | Sending data: dest=7 tag=17 Receiving result: source=7 tag=17 <- 3.60 | Sending data: dest=7 tag=18 Receiving result: source=7 tag=18 <- 3.80 | Sending data: dest=7 tag=19 Receiving result: source=7 tag=19 <- 4.00 | Sending data: dest=7 tag=20 Receiving result: source=8 tag= 7 <- 1.60 | Sending data: dest=8 tag=21 Receiving result: source=9 tag= 8 <- 1.80 | Sending data: dest=9 tag=22 Receiving result: source=1 tag= 9 <- 2.00 | Sending data: dest=1 tag=23 Receiving result: source=2 tag=10 <- 2.20 | Sending data: dest=2 tag=24 Receiving result: source=3 tag= 2 <- 0.60 | Sending data: dest=3 tag=25 Receiving result: source=4 tag=11 <- 2.40 | Sending data: dest=4 tag=26 Receiving result: source=5 tag=12 <- 2.60 | Sending data: dest=5 tag=27 Receiving result: source=6 tag=13 <- 2.80 | Sending data: dest=6 tag=28 Resulting vector Ab: 0.2 0.4 0.6 0.8 1.0 1.2 1.4 1.6 1.8 2.0 2.2 2.4 2.6 2.8 3.0 3.2 3.4 3.6 3.8 4.0 =Process 1: Vector b: ..., 0.01 Receiving data: tag= 0 | Sending result: tag= 0 -> 0.20 Receiving data: tag= 9 | Sending result: tag= 9 -> 2.00 Receiving data: tag=23 =Process 2: Vector b: ..., 0.01 Receiving data: tag= 1 | Sending result: tag= 1 -> 0.40 Receiving data: tag=10 | Sending result: tag=10 -> 2.20 Receiving data: tag=24 =Process 3: Vector b: ..., 0.01 Receiving data: tag= 2 | Sending result: tag= 2 -> 0.60 Receiving data: tag=25 =Process 4: Vector b: ..., 0.01 Receiving data: tag= 3 | Sending result: tag= 3 -> 0.80 Receiving data: tag=11 | Sending result: tag=11 -> 2.40 Receiving data: tag=26 =Process 5: Vector b: ..., 0.01 Receiving data: tag= 4 | Sending result: tag= 4 -> 1.00 Receiving data: tag=12 | Sending result: tag=12 -> 2.60 Receiving data: tag=27 =Process 6: Vector b: ..., 0.01 Receiving data: tag= 5 | Sending result: tag= 5 -> 1.20 Receiving data: tag=13 | Sending result: tag=13 -> 2.80 Receiving data: tag=28 =Process 7: Vector b: ..., 0.01 Receiving data: tag= 6 | Sending result: tag= 6 -> 1.40 Receiving data: tag=14 | Sending result: tag=14 -> 3.00 Receiving data: tag=15 | Sending result: tag=15 -> 3.20 Receiving data: tag=16 | Sending result: tag=16 -> 3.40 Receiving data: tag=17 | Sending result: tag=17 -> 3.60 Receiving data: tag=18 | Sending result: tag=18 -> 3.80 Receiving data: tag=19 | Sending result: tag=19 -> 4.00 Receiving data: tag=20 =Process 8: Vector b: ..., 0.01 Receiving data: tag= 7 | Sending result: tag= 7 -> 1.60 Receiving data: tag=21 =Process 9: Vector b: ..., 0.01 Receiving data: tag= 8 | Sending result: tag= 8 -> 1.80 Receiving data: tag=22
|
|
|
Разработка сайта: |
Последнее обновление: |