|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
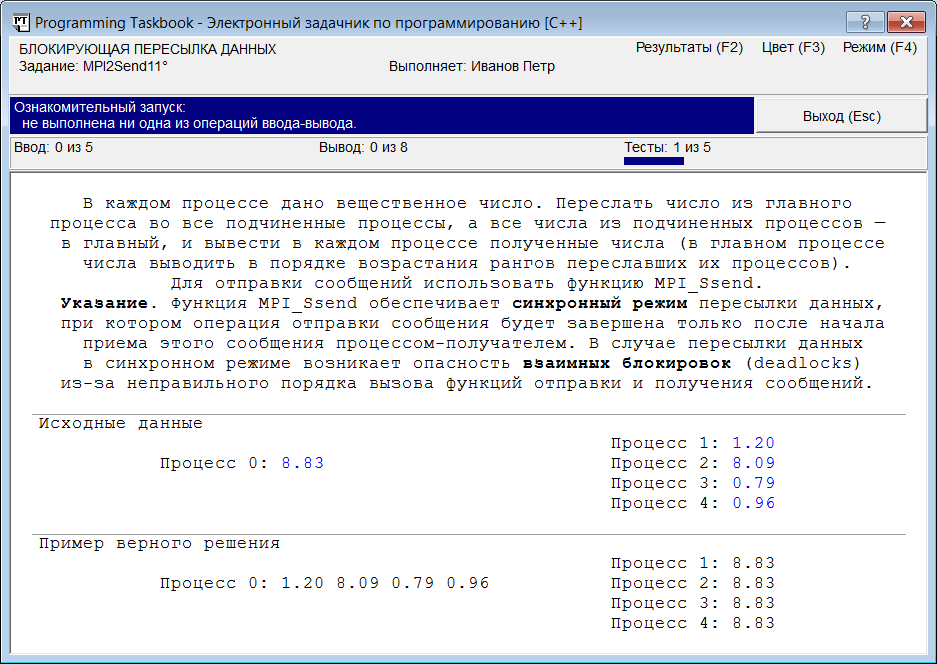
Пересылка сообщений между двумя процессами: MPI2Send11Теперь рассмотрим задание, связанное с пересылкой сообщений между различными процессами параллельной программы, и познакомимся с особенностями используемых для этого функций MPI. MPI2Send11. В каждом процессе дано вещественное число. Переслать число из главного процесса во все подчиненные процессы, а все числа из подчиненных процессов — в главный, и вывести в каждом процессе полученные числа (в главном процессе числа выводить в порядке возрастания рангов переславших их процессов). Для отправки сообщений использовать функцию MPI_Ssend. Указание. Функция MPI_Ssend обеспечивает синхронный режим пересылки данных, при котором операция отправки сообщения будет завершена только после начала приема этого сообщения процессом- получателем. В случае пересылки данных в синхронном режиме возникает опасность взаимных блокировок (deadlocks) из-за неправильного порядка вызова функций отправки и получения сообщений. Создадим проект-заготовку для выполнения этого задания и запустим полученную программу. Появившееся на экране окно задачника будет иметь вид, приведенный на следующем рисунке:
Для чтения исходных данных нам будет достаточно использовать единственную переменную вещественного типа, поскольку в каждом процессе дано только одно вещественное число. Исходные данные надо переслать в другие процессы параллельной программы. Для этого требуется использовать пару функций библиотеки MPI: одну для отправки сообщения, другую для его приема. Поскольку в данной подгруппе группы MPI2Send изучаются блокирующие варианты пересылки сообщений, для приема необходимо использовать функцию MPI_Recv. Для того чтобы отправить сообщение в блокирующем режиме, предусмотрено несколько видов функций; чаще всего используется функция MPI_Send, однако в нашем случае надо использовать функцию MPI_Ssend, поскольку об этом явным образом сказано в задании. Функция MPI_Ssend (как и другие функции для отправки сообщения, например MPI_Send) вызывается передающим процессом и определяет, какому процессу и какие данные он собирается переслать. Функция MPI_Recv вызывается принимающим процессом; в ней указываются процесс-отправитель и переменная-буфер, в которую будут записаны полученные от него данные. Вначале займемся приемом и пересылкой данных для подчиненных процессов, не реализуя пока действия, которые надо выполнить в главном процессе. Добавим в конец функции Solve следующий фрагмент кода: double a;
MPI_Status s;
if (rank > 0)
{
pt >> a;
MPI_Ssend(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
MPI_Recv(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &s);
pt << a;
}
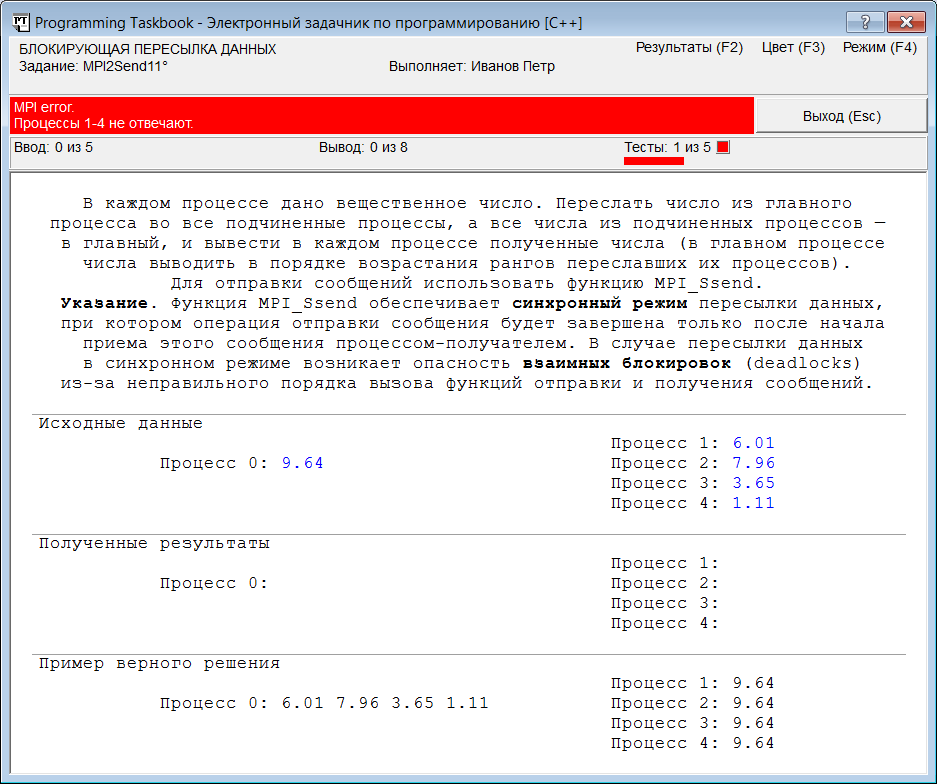
Обратите внимание на то, что в качестве первого параметра обеих функций указывается адрес той переменной, которая содержит (или должна принять) пересылаемые данные. Запустим нашу программу. Через 20–30 с после появления консольного окна с информацией о том, что программа запущена в параллельном режиме, на экране появится окно задачника с сообщением об ошибке в подчиненных процессах:
Сообщение об ошибке вида «MPI error. Процессы 1–4 не отвечают» означает, что главный процесс нашей параллельной программы не смог в течение определенного времени «связаться» с подчиненными процессами с целью получить от них информацию о введенных и выведенных в них данных (о том, как определить и изменить время ожидания отклика от подчиненных процессов, см. примечание 3 в разделе «Запуск программы»). Как следует из второй строки сообщения, ошибка возникла при попытке связаться со всеми подчиненными процессами (которых при данном запуске программы было четыре). Причина ошибки состоит в том, что функция MPI_Ssend отправки сообщения будет ожидать, пока принимающий (в данном случае главный) процесс вызовет соответствующую функцию приема (MPI_Recv), и только после этого выполнит пересылку данных с завершит свою работу (говорят, что функция MPI_Ssend обеспечивает синхронный режим пересылки). Но в нашей программе пока не содержится вызова функции MPI_Recv в главном процессе. Поэтому ожидание функции MPI_Ssend будет длиться вечно (точнее, пока выполнение подчиненных процессов не будет прекращено «насильственным образом»). Это пример зависания параллельной программы, возникающего обычно из-за того, что один или несколько процессов блокируются в ожидании информации, которая им не послана (в данном случае функция MPI_Ssend ожидает информацию о том, что главный процесс приступил к действиям по приему данных). Заметим, что если бы мы использовали для отправки сообщения другую функцию, например MPI_Bsend, которая не дожидается информации от принимающего процесса, а просто пересылает данные в специальный буфер отправки и сразу после этого завершает работу (так называемая пересылка в буферизованном режиме), то программа все равно бы зависла, но уже по другой причине: теперь функция MPI_Recv вечно ждала бы тех данных, которые должен был отправить ей главный процесс. Обратите внимание на то, что при закрытии окна задачника консольное окно останется на экране. Причина понятна: консольное окно управляется программой mpiexec, которая завершает работу только при завершении всех процессов запущенной параллельной программы, а в данном случае завершился только главный процесс (подчиненные процессы остаются заблокированными). Для завершения программы mpiexec и закрытия консольного окна необходимо нажать несколько раз комбинацию клавиш Ctrl+C или Ctrl+Break (как сказано в комментарии, выведенном в консольном окне). Примечание 1. При «аварийном» завершении программы mpiexec в памяти могут остаться запущенные (и зависшие) процессы параллельной программы. Это в дальнейшем будет препятствовать перекомпиляции нашей программы, поскольку, пока процесс находится в памяти, связанный в ним exe-файл недоступен для изменения. Однако при выполнении заданий с использованием задачника PT for MPI-2 такой проблемы не возникает: вспомним о том, что программу mpiexec запустила наша программа (которая сама была запущена из интегрированной среды). Этот «непараллельный» экземпляр нашей программы остается в памяти, пока программа mpiexec не завершит работу, после чего он выгружает из памяти все зависшие процессы. Если бы эта полезная работа не выполнялась задачником, то выгружать каждый из зависших процессов пришлось бы вручную, используя диспетчер задач Windows. Итак, мы познакомились с ситуацией, когда один или несколько подчиненных процессов оказываются заблокированными. Такая же «неприятность» может произойти и с главным процессом. Дополним нашу программу фрагментом, связанным с главным процессом, причем в этом фрагменте также организуем вызов MPI-функций в том же самом («естественном») порядке — вначале отправка данных, затем прием: else
{
pt >> a;
for (int i = 1; i < size; ++i)
MPI_Ssend(&a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
for (int i = 1; i < size; ++i)
{
MPI_Recv(&a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, &s);
pt << a;
}
}
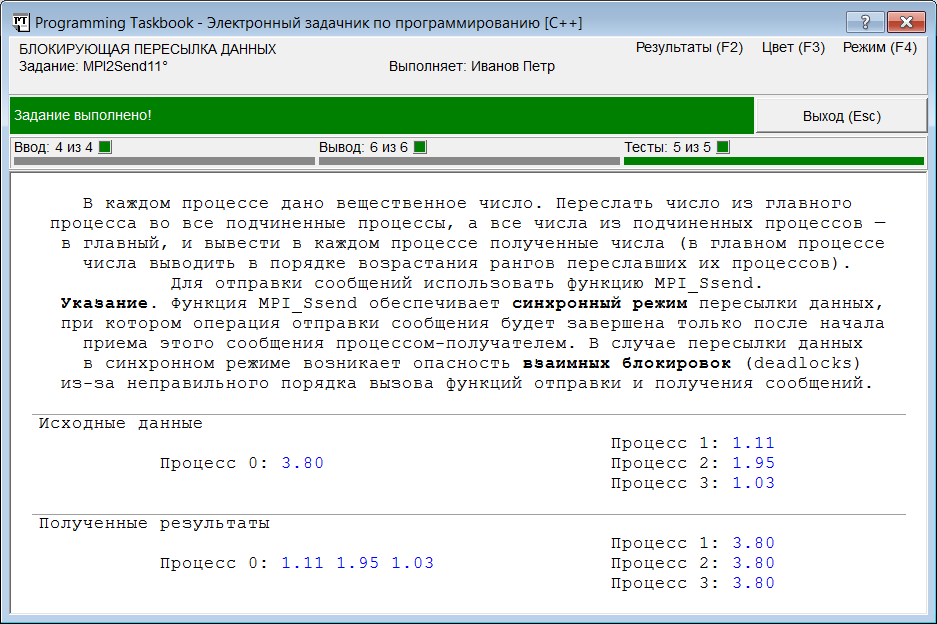
Если запустить эту программу, то после появления консольного окна можно ожидать сколько угодно, однако окно задачника на экране не появится. Это связано с тем, что заблокированным оказался главный процесс нашей параллельной программы: перед отображением окна задачника главный процесс должен выполнить тот фрагмент программы, который разработан для него учащимся, а в нашем случае этот фрагмент привел к блокировке. Поэтому главный процесс просто не дошел до того места программы, в котором выполняется вывод окна задачника на экран. Почему опять возникает блокировка? Ведь теперь, казалось бы, каждый процесс готов и отправить, и принять сообщение. Однако для того чтобы завершилась функция MPI_Ssend, реализующая синхронный режим отправки, необходимо, чтобы в процессе-получателе уже была вызвана функция приема MPI_Recv, а дойти до этой функции процесс-получатель не может, так как в нем тоже вызвана функция MPI_Ssend. Такое явление носит название взаимной блокировки (англ. deadlock). Если в течение 20–30 с окно задачника не появилось, то можно считать, что произошло зависание главного процесса. В такой ситуации, как и в ситуации, описанной ранее, необходимо явным образом прервать выполнение параллельной программы, нажав несколько раз Ctrl+C или Ctrl+Break. Примечание 2. Любой из описанных выше «аварийных» способов завершения программы фиксируется задачником в файле результатов. Однако в случае если произошло зависание только подчиненных процессов (и на экране появилось окно задачника), в файл результатов будет записан текст «MPI error», тогда как в случае зависания главного процесса текст будет другим: «Выполнение задания прервано». Простейший способ исправить нашу программу — это стереть вторую букву «s» в имени хотя бы одной функции MPI_Ssend, т. е. заменить либо в подчиненных, либо в главном процессе вызов функции MPI_Ssend на вызов функции MPI_Send, реализующей не синхронный, а стандартный режим отправки данных. Это связано с тем, что в библиотеке MPI системы MPICH стандартный режим, как и режим с буферизацией, использует буфер для хранения отправляемых данных (только в отличие от режима с буферизацией этот стандартный буфер создается автоматически). После пересылки данных в стандартный буфер функция MPI_Send завершает работу, даже если к этому моменту принимающий процесс не вызвал функцию MPI_Recv. Получается такая последовательность действий (будем считать, что мы изменили функцию MPI_Ssend на MPI_Send в подчиненных процессах). В каждом из подчиненных процессов вызывается функция MPI_Send; она обеспечивает копирование пересылаемых данных в стандартный буфер, после чего немедленно завершает работу; после этого вызывается функция MPI_Recv, которая ожидает приема данных от главного процесса. В это же время в главном процессе в цикле вызывается функция MPI_Ssend, которая приостанавливает выполнение, пока в подчиненных процессах не будет вызвана функция MPI_Recv. Но функция MPI_Recv в подчиненных процессах обязательно будет вызвана, в этот момент функция MPI_Ssend в главном процессе осуществляет отправку данных и завершает работу. Таким образом, все функции MPI_Ssend в цикле успешно проработают, после чего в главном процессе во втором цикле будут вызваны функции MPI_Recv, которые примут те данные от подчиненных процессов, которые ранее были помещены в стандартный буфер. Наконец, после завершения работы функций MPI_Ssend в главном процессе успешно выполнятся и ожидающие получения данных функции MPI_Recv в подчиненных процессах. Итак, никакой взаимной блокировки не произойдет. При запуске исправленной программы она будет успешно протестирована на пяти наборах исходных данных, после чего будет выведено окно задачника с сообщением о том, что задание выполнено:
Однако описанное выше исправление не вполне соответствует условию задачи, поскольку в условии требовалось использовать только функции MPI_Ssend. Вариант исправления с сохранением функции MPI_Ssend состоит в том, что либо во фрагменте программы для подчиненных процессов, либо во фрагменте программы для главного процесса надо изменить порядок вызова функций отправки и приема сообщения. Например, можно изменить порядок вызова функций в главном процессе: double a;
MPI_Status s;
if (rank > 0)
{
pt >> a;
MPI_Ssend(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
MPI_Recv(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &s);
pt << a;
}
else
{
for (int i = 1; i < size; ++i)
{
MPI_Recv(&a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, &s);
pt << a;
}
pt >> a;
for (int i = 1; i < size; ++i)
MPI_Ssend(&a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
}
В данной ситуации взаимная блокировка также будет отсутствовать. Действительно, в главном процессе сразу вызываются функции MPI_Recv, поэтому в подчиненном процессе соответствующие функции MPI_Ssend успешно проработают и передадут данные в главный процесс, которые в нем будут приняты. Затем в подчиненных процессах, в свою очередь, будут вызваны функции MPI_Recv, которые позволят успешно проработать функциям MPI_Ssend в главном процессе. Примечание 3. Описанный вариант исправления имеет еще одно преимущество. Дело в том, что в стандарте MPI не гарантируется, что функция MPI_Send обязательно будет использовать буфер для промежуточного хранения пересылаемых данных. Это определяется самой исполняющей средой MPI, поэтому возможна ситуация, когда функция MPI_Send будет применять не буферизованный, а синхронный режим пересылки; в этом случае по-прежнему будет возникать взаимная блокировка. Полученную программу можно упростить, если в разделе else
воспользоваться вспомогательной вещественной переменной b для
получения данных из подчиненных процессов. Это позволит разместить
оператор ввода double a;
MPI_Status s;
pt >> a;
if (rank > 0)
{
MPI_Ssend(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
MPI_Recv(&a, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD, &s);
pt << a;
}
else
for (int i = 1; i < size; ++i)
{
double b;
MPI_Recv(&b, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, &s);
pt << b;
MPI_Ssend(&a, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);
}
}
Еще одного небольшого упрощения можно добиться, удалив описание переменной s типа MPI_Status и заменив параметр &s в функциях MPI_Recv на специальный указатель-«заглушку» MPI_STATUS_IGNORE. Значение MPI_STATUS_IGNORE удобно использовать в ситуации, когда в программе не требуется обращаться к информации, предоставляемой параметром типа MPI_Status. Примечание 4. Константа MPI_STATUS_IGNORE появилась в стандарте MPI-2, поэтому при использовании системы MPICH 1.2.5, реализующей стандарт MPI-1, ее применять не следует. Заметим, что более эффективное решение этого задания можно получить, используя коллективные операции пересылки данных.
|
|
|
Разработка сайта: |
Последнее обновление: |