|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
Выполнение задания на обработку строк: String9Особенности выполнения заданий на обработку символов и строк рассмотрим на примере задания String9. String9°. Дано четное число N (> 0) и символы C1 и C2. Вывести строку длины N, которая состоит из чередующихся символов C1 и C2, начиная с C1. Создание программы-заготовки и знакомство с заданиемПрограмму-заготовку для решения задания String9 можно создать с помощью модуля PT4Load. Программа, созданная для задания String9, имеет следующий вид: [Python] from pt4 import *
def solve():
task("String9")
start(solve)
[R] source("PT4.R")
Solve <- function() {
Task("String9")
}
Start(Solve)
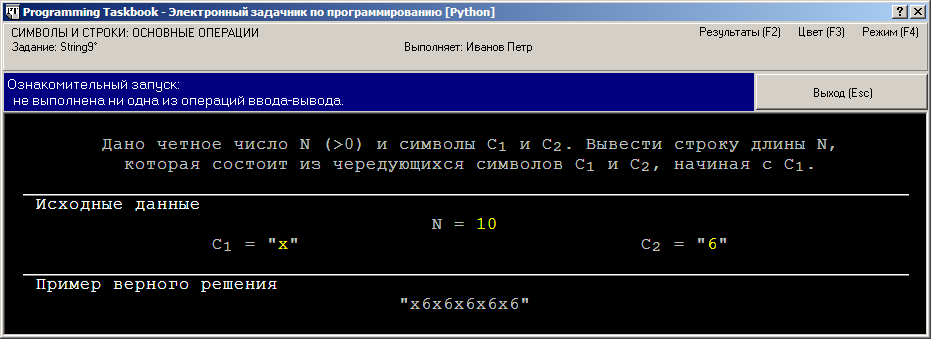
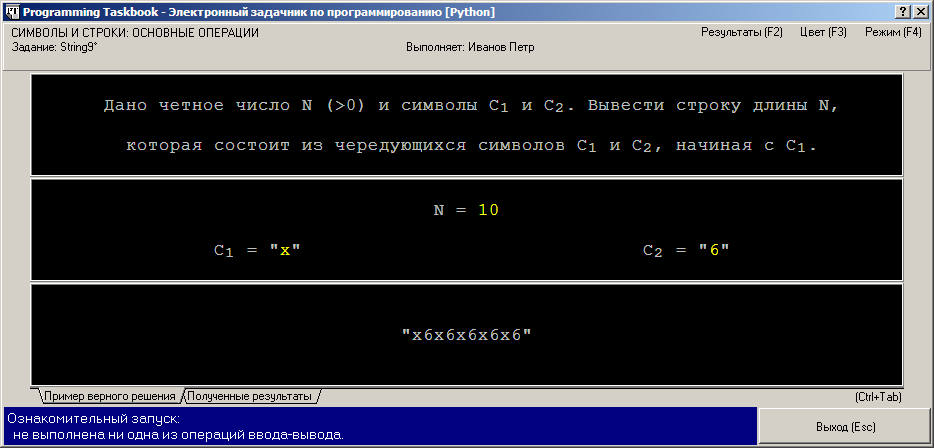
Запустим программу, нажав клавишу [F5] при работе в среде IDLE, Wing IDE и VS Code или комбинацию [Ctrl]+[Shift]+[S] при работе в RStudio. После запуска программы на экране появится окно задачника. На рисунке приведены два варианта представления окна для языка Python — в режиме с динамической и с фиксированной компоновкой:
Символьные и строковые данные в окне задачника для языков Python и R заключаются в двойные кавычки; это позволяет отличить числовые данные (например, 2) от символьных и строковых данных, содержащих цифры (например, символа "2"). Кроме того, кавычки дают возможность увидеть пробелы, находящиеся в начале или в конце строк. Ввод исходных данныхДобавим в программу фрагмент, обеспечивающий ввод исходных данных. Вначале проиллюстрируем возможности специализированных функций ввода, имеющихся в задачнике для языка Python, и воспользуемся функциями get_str и get_int: [Python] def solve():
task("String9")
a = get_str()
b = get_str()
n = get_int()
Мы намеренно ввели данные не в том порядке, в котором они указаны в окне задачника. Запуск нового варианта программы уже не будет считаться ознакомительным, поскольку в программе выполняется ввод исходных данных. Так как порядок ввода исходных данных является ошибочным, этот вариант решения будет признан неверным и приведет к сообщению «Неверно указан тип при вводе исходных данных. Для ввода 1-го элемента (целого типа) использована переменная символьного типа». Напомним правило, определяющее порядок ввода и вывода данных для задачника Programming Taskbook: ввод и вывод данных производится по строкам (слева направо), а строки просматриваются сверху вниз. Примечание. Если бы для ввода исходных данных использовалась «универсальная» функция get, то задачник не обнаружил бы ошибок ввода, однако в результате в переменную a было бы записано целое число, а в переменные b и n — символы. Таким образом, содержимое переменных не соответствовало бы их назначению, что в дальнейшем обязательно привело бы к неправильной работе алгоритма, использующего эти переменные. Приведенный пример показывает преимущества использования специализированных функций ввода, позволяющих сразу распознать типичные ошибки при чтении исходных данных. Исправим программу, изменив в ней порядок ввода: [Python] def solve():
task("String9")
n = get_int()
a = get_str()
b = get_str()
Теперь исходные данные вводятся правильно. Первый этап решения задачи пройден. Следует заметить, что если использовать вариант get3 универсальной функции ввода, то текст фрагмента можно существенно сократить: в на [Python] def solve():
task("String9")
n, a, b = get3()
В случае языка R мы три раза вызовем функцию Get, сохранив ее возвращаемые значения в трех переменных, указанных в правильном порядке: [R] Solve <- function() {
Task("String9")
n <- Get()
a <- Get()
b <- Get()
}
Формирование требуемой строки и ее выводДля формирования нужной строки в варианте для языка Python воспользуемся операцией «+» сцепления строк. В языке R для сцепления строк предусмотрена очень гибкая функция paste, позволяющая указывать несколько аргументов-строк и определять добавляемый между ними разделитель. Поскольку по умолчанию разделителем считается пробел, необходимо явно указать, что в нашем случае разделителем является пустая строка. Для вывода полученной строки используем функцию put:
[Python] def solve():
task("String9")
n, a, b = get3()
s = ""
for i in range(n)
s += a + b
put(s)
[R] Solve <- function() {
Task("String9")
n <- Get()
a <- Get()
b <- Get()
s <- ""
for i in 1:n
s <- paste(s, a, b, sep = "")
Put(s)
}
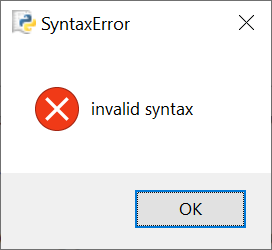
В каждом из приведенных вариантов мы допустили по одной ошибке, которые будут препятствовать успешному запуску программы. Эти ошибки связаны с заголовком цикла for. При попытке запуска программы на языке Python на экран будет выведено окно с сообщением о синтаксической ошибке в программе:
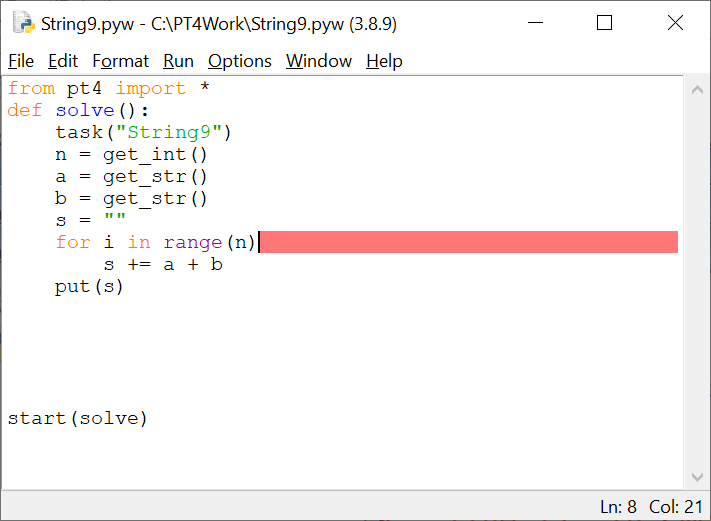
Подобные сообщения выводятся средой IDLE в случае обнаружения синтаксических ошибок, препятствующих запуску программы. При закрытии диалогового окна в окне с программой будет выделена строка, в которой была найдена ошибка:
В данном случае ошибка заключается в том, что в конце выделенной строки отсутствует двоеточие. При попытке запуска программы на языке R сообщение об ошибке будет выведено в разделе Console: Ошибка в source("C:/PT4Work/String9.R") :
C:/PT4Work/String9.R:8:7: неожиданный символ
7: s <- ""
8: for i
^
Кроме того, ошибочная строка в редакторе будет помечена слева символом ошибки (заметим, что для появления этого символа даже не потребуется выполнять попытку запуска). Ошибка связана с тем, что выражение после слова for в заголовке цикла должно заключаться в круглые скобки. После исправления отмеченных ошибок программу уже можно будет запустить на выполнение. Однако при ее запуске в области результатов будет выведена строка, оканчивающаяся особым символом — красной звездочкой, например: "a1a1a1a1a1* Красная звездочка, расположенная в конце строки, отображаемой на экране, означает, что длина полученной строки превышает длину контрольной (т. е. «правильной») строки. Для того чтобы увидеть на экране всю полученную строку, достаточно подвести курсор мыши к строке со звездочкой; при этом полный текст строки появится во всплывающей подсказке.
Примечание. Красная звездочка может появиться и при выводе ошибочных числовых данных. Например,
если ожидается целое число в диапазоне от 1 до 99, а получено число 10000, то на экран будет выведена только
первая цифра этого числа, за которой будет указана красная звездочка: Правильное решение, его тестирование и просмотр результатовОшибка в предыдущей программе возникла из-за неверного указания количества итераций цикла. Действительно, на каждой итерации к строке добавляется по два символа, поэтому после n итераций строка будет содержать 2n символов (а не n, как требуется в задании). Для исправления ошибки достаточно вдвое уменьшить число итераций, изменив заголовок цикла следующим образом: [Python] for i in range(n // 2): [R] for (i in 1:(n/2)) В варианте для языка Python мы использовали специальную операцию целочисленного деления «//». Заметим, что в версиях 2.x можно было бы использовать и обычную операцию деления «/», поскольку в этих версиях при наличии обоих операндов целого типа операция «/» означает операцию целочисленного деления. Однако в языке Python версий 3.x операция «/» всегда всегда означает деление с вещественным результатом, поэтому для выполнения целочисленного деления необходимо пользоваться операцией «//» (в Python 3.x при попытке использования в указанном выше операторе заголовка цикла операции «/» мы получили бы сообщение об ошибке типа TypeError: «'float' object cannot be interpreted as an integer»). В варианте для языка R мы использовали «обычную» операцию деления (заметим, что и константа 2, указанная в выражении n/2 считается вещественной константой). Поэтому ее результатом будет вещественное число. Однако выражения, указываемые в операции диапазона «:», автоматически преобразуются к целому типу, поэтому итоговое число итераций будет правильным.
Примечание. В языке R тоже имеется операция целочисленного деления,
для которой предусмотрено не очень наглядное обозначение После запуска исправленной программы и успешного прохождения 5 тестов мы получим сообщение «Задание выполнено!». Нажав клавишу [F2], мы можем вывести на экран окно результатов, в котором будут перечислены все наши попытки решения задачи (буква «y», которая указывается перед датой, означает, что при выполнении задания использовался язык Python): String9 y06/09 15:46 Ознакомительный запуск. String9 y06/09 15:50 Неверно указан тип при вводе исходных данных. String9 y06/09 15:55 Запуск с правильным вводом данных. String9 y06/09 16:00 Ошибочное решение. String9 y06/09 16:05 Задание выполнено! Обратите внимание на то, что сообщения об обнаружении синтаксической ошибки (отсутствии двоеточия) в данном списке нет, так как при наличии синтаксических ошибок программа не запускается на выполнение, и поэтому задачник не получает от нее никакой информации. Вместо цикла for в программе можно было бы использовать цикл while, повторяя его итерации до тех пор, пока длина строки не станет равной n. В этом случае нет необходимости прибегать к операции целочисленного деления. Обратите внимание на то, что в языке R для определения длины строки надо использовать функцию nchar, а не length, поскольку функция length возвращает длину вектора s (который в данном случае состоит из единственной строки, и поэтому его длина будет равна 1). [Python] def solve():
task("String9")
n, a, b = get3()
s = ""
while len(s) < n:
s += a + b
put(s)
[R] Solve <- function() {
Task("String9")
n <- Get()
a <- Get()
b <- Get()
s <- ""
while (nchar(s) < n)
s <- paste(s, a, b, sep = "")
Put(s)
}
С другой стороны при решении задачи можно вообще обойтись без цикла, если воспользоваться специальной возможностью языка Python: операцией «*», которую можно применять к двум операндам: n (целому числу) и s (строке). Результатом операции n * s (как и s * n) будет строка, содержащая n копий исходной строки s. Таким образом, после ввода исходных данных (который можно организовать в виде одного оператора) в нашей программе останется лишь применить эту операцию: [Python] def solve():
task("String9")
n, a, b = get3()
s = n // 2 * (a + b)
put(s)
Более того, поскольку в используемое выражение можно передать вызовы функций ввода, а результат сразу указать в качестве параметра функции put, данный вариант решения можно сжать до одного оператора (не считая операторов импортирования модуля pt4 и вызова функции task): [Python] def solve():
task("String9")
put(get() // 2 * (get() + get()))
В случае языка R мы можем использовать векторную функцию strrep(x, times), которая позволяет дублировать все элементы строкового вектора x столько раз, каково значение соответствующего элемента числового вектора times, и возвращает преобразованный вектор. В нашем случае оба параметра будут векторами длины 1, а результат можно сразу передать в функцию Put: [R] Solve <- function() {
Task("String9")
n <- Get()
a <- Get()
b <- Get()
Put(strrep(paste(a, b, sep = ""), n / 2))
}
|
|
|
Разработка сайта: |
Последнее обновление: |