|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
Выполнение заданий на обработку файловДанная страница содержит подробное описание процесса решения типовой задачи на обработку двоичных файлов с числовой информацией, а также примеры решения задач на обработку строковых и текстовых файлов. Двоичные файлы с числовой информацией: File48Особенности выполнения заданий на обработку файлов рассмотрим на примере задания File48. File48°. Даны три файла целых чисел одинакового размера с именами SA, SB, SC и строка SD. Создать новый файл с именем SD, в котором чередовались бы элементы исходных файлов с одним и тем же номером: A1, B1, C1, A2, B2, C2, ... . Создание программы-заготовки и знакомство с заданиемНапомним, что программу-заготовку для решения задания можно создать с помощью модуля PT4Load, используя ярлык PT4Load, находящийся в рабочем каталоге. В созданный проект будет входить файл File48.rb. Приведем текст функции solve из данного файла (именно в эту функцию требуется ввести решение задачи): [Ruby] def solve()
task "File48"
end
[Julia] function solve()
task("File48")
end
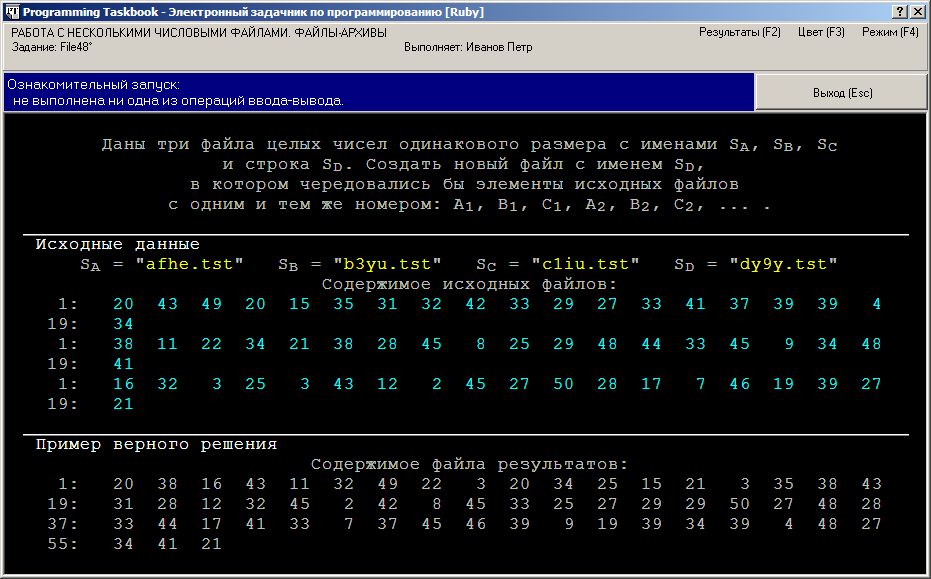
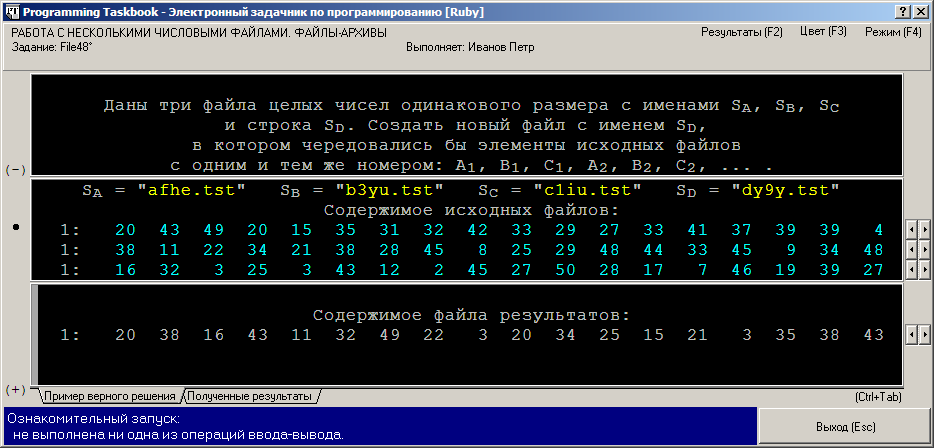
После запуска программы на экране появится окно задачника. На рисунке приведены два варианта представления окна — в режиме с динамической и с фиксированной компоновкой:
В первой строке раздела исходных данных указаны имена трех исходных файлов (SA, SB и SC) и одного результирующего (SD). В последующих строках раздела исходных данных показано содержимое исходных файлов. Элементы файлов отображаются бирюзовым цветом, чтобы подчеркнуть их отличие от обычных исходных данных (желтого цвета) и комментариев (светло-серого цвета). В режиме с фиксированной компоновкой для отображения содержимого каждого двоичного файла отводится по одной строке. Поскольку размер файлов, как правило, превышает количество элементов, которое может уместиться на одной экранной строке, в режиме с фиксированной компоновкой предусмотрена возможность прокрутки (листания) элементов файла с помощью мыши или клавиатуры. В режиме с динамической компоновкой на экране отображаются все элементы двоичных файлов, даже если для этого требуется использовать более одной экранной строки; при этом в начале каждой строки указывается порядковый номер первого элемента файла, приведенного в данной строке (элементы нумеруются от 1). Следует заметить, что при каждом запуске программы с учебным заданием исходные файлы создаются под новыми именами и заполняются новыми данными, а исходные и результирующие файлы, созданные при предыдущем запуске программы, удаляются с диска. Вернемся к нашей программе, только что запущенной на выполнение. Так как в ней не указаны операторы ввода-вывода, запуск программы считается ознакомительным, проверка решения не производится, а на экране отображается пример верного решения (в нашем случае это числа, которые должны содержаться в результирующем файле при правильном решении задачи). Ввод исходных данныхДобавим в программу фрагмент, позволяющий ввести имена файлов и связать с этими файлами соответствующие файловые переменные. Поскольку мы собираемся работать с четырьмя файлами одного типа, удобно предусмотреть массив для хранения всех файловых переменных: [Ruby] def solve()
task "File48"
f = []
for i in 0..2
f.push(File.open(get_s, "rb"))
end
#
f.each {|e| e.close}
end
[Julia] function solve()
task("File48")
f = Vector{IOStream}(undef, 3)
for i in 1:length(f)
f[i] = open(get(), "r")
end
#
for e in f
close(e)
end
end
Мы намеренно ограничились тремя итерациями цикла, оставив непрочитанным имя результирующего файла. Прочитанное имя файла сразу передается функции open (методу класса File в случае языка Ruby), которая открывает указанный файл в требуемом режиме и возвращает его дескриптор. Для языка Ruby этот дескриптор добавляется к массиву f с помощью метода push, а для языка Julia он просто записывается в элемент массива с соответствующим индексом, поскольку при описании массива f для него уже была выделена память для хранения трех элементов (обратите внимание на то, что в языке Julia, в отличие от большинства современных языков, индексирование всех коллекций выполняется не от 0, а от 1). Режим открытия файла в виде текстовой строки указывается во втором параметре функции open. Для Ruby строка содержит две буквы: r — режим чтения файла (read) и b — указание на то, что файл является двоичным (бинарным, binary), для Julia особое указание бинарного режима работы с файлом не требуется. В конце программы мы добавили оператор, в котором закрываются все открытые файлы. В Ruby мы для этого воспользовались итератором each, вызвав его для массива f и передав ему блок, в котором для каждого элемента массива e указали требуемое действие (закрытие файла методом close). В Julia то же самое действие мы реализовали с помощью цикла по элементам массива f. Заметим, что в языке Ruby функцию open можно вызывать, не указывая перед ней имя класса File,
а в языке Jylia в заголовке цикла for по числовому диапазону можно вместо слова in использовать символ =,
например, Комментарий # расположен в том месте программы, в котором можно выполнять операции ввода-вывода для файлов: они уже открыты функцией open и еще не закрыты функцией close. Запуск нового варианта программы уже не будет считаться ознакомительным, поскольку в программе выполняется ввод исходных данных. Так как имя результирующего файла осталось непрочитанным, этот вариант решения будет признан неверным и приведет к сообщению «Введены не все требуемые исходные данные. Количество прочитанных данных: 3 (из 4)». Пример программы, приводящей к ошибке времени выполненияИзменим программу, увеличив размер обрабатываемого массива f до 4 элементов. Для этого в случае языка Ruby достаточно заменить в заголовке цикла число 2 на 3, а в случае языка Julia — заменить в описании вектора f число 3 на 4. После запуска программы окно задачника будет содержать сообщение об ошибке. В случае Ruby сообщение будет иметь вид «Error Errno: ENOENT: (Errno 2) No such file or directory: 'dp1u.tst'», в случае Julia — «Error SystemError: opening file "dp1u.tst": No such file or directory» (имя файла, разумеется, может отличаться от приведенного). Ошибка произошла из-за того, что на четвертой, последней итерации цикла, программа попыталась открыть в режиме чтения файл с именем dp1u.tst, который отсутствует на диске (это именно тот файл, который должна создать наша программа). Создание пустого результирующего файлаДля того чтобы избежать ошибки времени выполнения, отсутствующий файл результатов следует создать, после чего открыть в режиме записи (w). Для Ruby по-прежнему надо указывать и символ b, поскольку создаваемый файл также должен обрабатываться как двоичный. Добавим в программу тернарный оператор, определяющий по номеру параметра цикла i режим открытия файла: [Ruby] def solve()
task "File48"
f = []
for i in 0..3
f.push(File.open(get_s, i < 3 ? "rb" : "wb"))
end
#
f.each {|e| e.close}
[Julia] function solve()
task("File48")
f = Vector{IOStream}(undef, 3)
for i in 1:length(f)
f[i] = open(get(), i < 4 ? "r" : "w")
end
#
for e in f
close(e)
end
end
Запуск нового варианта программы не приведет к ошибке времени выполнения; более того,
результирующий файл будет создан. Однако созданный файл останется пустым,
т. е. не содержащим ни одного элемента.
Начиная с версии 4.15, в этом случае на информационной панели выводится сообщение (на светло-синем фоне):
«Запуск с правильным вводом данных: все требуемые данные введены, результирующий файл является
пустым» (в предыдущих версиях в этой ситуации на информационной панели выводилось сообщение
«Ошибочное решение», а в строке, которая должна содержать элементы
результирующего файла, отображался текст Таким образом, нам осталось реализовать фрагмент алгоритма, обеспечивающий ввод и вывод файловых данных. Чтение и запись данных из двоичных файловВначале обсудим действия для языка Ruby. Поскольку мы собираемся читать двоичные данные, нам необходимо использовать функцию read с параметром — целым числом, определяющим, какое число байт следует прочесть из исходного файла (в отличие от большинства языков программирования, в Ruby не предусмотрено возможности непосредственного чтения числовых данных из двоичных файлов). Поскольку одно целое число в двоичном файле кодируется четырьмя байтами, нам необходимо использовать функцию read с параметром 4. Результат, возвращенный этой функцией (двоичная строка), можно сразу передавать в качестве параметра функции write для записи в создаваемый двоичный файл. Таким образом, для считывания одного целого числа из каждого исходного файла и записи его в результирующий файл, нам достаточно добавить в раздел программы, помеченный комментарием #, следующий фрагмент: [Ruby] for i in 0..2
f[3].write(f[i].read(4))
end
Язык Julia содержит средства, позволяющие считывать из двоичных файлов числовые данные требуемого типа. В нашем случае надо использовать тип Int32, так как во всех заданиях на обработку файлов целых чисел предполагается, что числа имеют размер 4 байта (32 бита): [Julia] for i in 1:3
write(f[4], read(f[i], Int32))
end
Запустив исправленную программу, мы получим все еще неверный, но ожидаемый результат: созданный файл будет содержать три элемента, совпадающих с начальными элементами исходных файлов. Правильное решение, его тестирование и просмотр результатовДля получения правильного решения нам необходимо повторить несколько раз приведенный ранее фрагмент программы, обеспечивающий считывание одного числа из каждого исходного файла и его запись в результирующий файл. В языке Ruby для определения размера файла в байтах достаточно воспользоваться функцией size класса File, передав ей в качестве параметра имя файла (имя, в свою очередь, можно получить из дескриптора файла, вызвав для него метод path). В языке Julia для тех же целей предусмотрена функция filesize, параметром которой может быть сам дескриптор файла. При организации цикла необходимо учесть, что количество итераций должно быть равно len / 4, где len — размер файла в байтах (поскольку каждый элемент файла занимает 4 байта). Получаем один из вариантов правильного решения: [Ruby] def solve()
task "File48"
f = []
for i in 0..3
f.push(File.open(get_s, i < 3 ? "rb" : "wb"))
end
len = File.size f[0].path
(len / 4).times do
for i in 0..2
f[3].write(f[i].read(4))
end
end
f.each {|e| e.close}
end
[Julia] function solve()
task("File48")
f = Vector{IOStream}(undef, 4)
for i in 1:length(f)
f[i] = open(get(), i < 4 ? "r" : "w")
end
for j in 1:filesize(f[1]) ÷ 4
for i in 1:3
write(f[4], read(f[i], Int32))
end
end
for e in f
close(e)
end
end
Следует обратить внимание на то, что в языке Julia для операции деления нацело используется
особый символ ÷, отсутствующий на клавиатуре. Для его ввода в программу надо набрать текст В данном варианте решения мы учли, что по условию задачи все исходные файлы имеют одинаковый размер. После запуска этого варианта программы и успешного прохождения 5 тестов мы получим сообщение «Задание выполнено!». Нажав клавишу [F2], мы можем вывести на экран окно результатов, в котором будут перечислены все наши попытки решения задачи: File48 r07/09 11:19 Ознакомительный запуск. File48 r07/09 11:22 Введены не все требуемые исходные данные. File48 r07/09 11:24 Error Errno::ENOENT. File48 r07/09 11:26 Запуск с правильным вводом данных. File48 r07/09 11:28 Ошибочное решение. File48 r07/09 12:33 Задание выполнено! Символ «r» означает, что программа выполнялась на языке Ruby. Для языка Julia используется символ «u» (поскольку символ «j» зарезервирован для языка Java). При выходе из среды NetBeans можно убедиться в том, что из рабочего каталога удалены все исходные и результирующие файлы, которые создавались и обрабатывались при выполнении задания.
Примечание. Задачу можно решить и не используя функцию
File.size (для языка Ruby) или функцию filesize (для языка Julia), если
воспользоваться полезной функцией, возвращающей значение true, если достигнут конец файла (англ. End of File, EOF).
Такая функция имеется и в языке Ruby, и в языке Julia. В языке Ruby она имеет имя eof?
и вызывается как метод файлового дескриптора f: [Ruby] def solve()
task "File48"
f = []
for i in 0..3
f.push(File.open(get_s, i < 3 ? "rb" : "wb"))
end
while not f[0].eof? do
for i in 0..2
f[3].write(f[i].read(4))
end
end
f.each {|e| e.close}
end
[Julia] function solve()
task("File48")
f = Vector{IOStream}(undef, 4)
for i in 1:length(f)
f[i] = open(get(), i < 4 ? "r" : "w")
end
while !eof(f[1])
for i in 1:3
write(f[4], read(f[i], Int32))
end
end
for e in f
close(e)
end
end
Заметим, что вместо конструкции Получение числовых значений из двоичных файлов, преобразование файла: File25В предыдущем пункте нам удалось выполнить задание на языке Ruby, не «расшифровывая» содержимое двоичных файлов: нам было достаточно знать, что размер каждого элемента файла равен 4 байтам. Однако во многих ситуациях приходится обрабатывать числовые значения, полученные из двоичных файлов, поэтому необходимо уметь «раскодировать» двоичные числовые форматы, в которых хранятся числовые данные в двоичных файлах, а также «кодировать» числа для последующей записи их в двоичные файлы. Для кодирования/декодирования двоичной информации в языке Ruby предусмотрены
специальные методы pack(fmt) и unpack(fmt).
Метод unpack определен для двоичных строк
(возвращаемых, в частности, методом read); он преобразует двоичную строку в массив
данных в соответствии с форматом fmt, указанным в качестве параметра метода.
Для 4-байтного знакового числа целого типа предусмотрен формат Познакомимся с использованием этих функций, выполняя задание File25 — первое из заданий группы File, связанное с преобразованием исходного файла: File25°. Дан файл вещественных чисел. Заменить в нем все элементы на их квадраты. Преобразовать файл можно двумя способами: либо открыть файл одновременно на чтение и запись и сразу записывать в него ранее считанные и преобразованные значения, либо воспользоваться вспомогательным файлом (в этом случае исходный файл открывается только на чтение, а преобразованные значения записываются во вспомогательный файл). При использовании вспомогательного файла дополнительно потребуется выполнить два завершающих действия: удалить исходный файл и переименовать вспомогательный файл, присвоив ему имя исходного. Второй способ является более универсальным, поскольку может использоваться для самых разных видов преобразований файла, в том числе и таких, которые связаны с удалением или добавлением элементов. Однако в простых случаях можно обойтись без вспомогательного файла, хотя при этом придется использовать прямой доступ к элементам файла (с помощью функции seek) и учитывать ряд особенностей, связанных с одновременным доступом к файлу и на чтение, и на запись. Вначале приведем пример решения, не использующего вспомогательный файл: [Ruby] def solve()
task "File25"
f = File.open get_s, "r+b"
until f.eof? do
s = f.read 8
x = s.unpack "d"
f.pos -= 8
f.write([x[0]**2].pack "d")
end
f.close
end
В данной программе исходный двоичный файл открывается одновременно и на чтение, и на запись; это обеспечивается
указанием специального режима открытия файла Для перебора всех элементов файла используется цикл while, который завершится в тот момент, когда после обработки очередного набора данных будет обнаружен конец файла. Набор байт, считанный из файла на каждой итерации, распаковывается функцией unpack. Ее результатом является массив x, состоящий из единственного элемента x[0] (поскольку мы считываем данные порциями по 8 байт). Перед записью числа x[0]**2 (т. е. исходного значения, возведенного в квадрат), необходимо выполнить два действия. Во-первых, надо «вернуться» в файле на 8 байт назад, чтобы квадрат числа был записан поверх его исходного значения (если этого не сделать, то квадрат будет записан поверх следующего файлового элемента). Это действие выполняется с помощью свойства pos файлового дескриптора, которое доступно для чтения и для записи и содержит текущую позицию файлового указателя в байтах, отсчитанных от начала файла. Во-вторых, необходимо перевести полученное число в кодирующий его набор байт; это действие выполняется методом pack, который применяется к массиву, состоящему из единственного элемента. Заметим, что вместо свойства pos для перехода к требуемой файловой позиции можно также использовать метод seek c двумя параметрами: первый задает номер n новой позиции, а второй — определяет точку отсчета и может принимать три значения: IO::SEEK_SET (отсчет от начала файла, номер n должен быть неотрицательным), IO::SEEK_END (отсчет от конца файла, номер n должен быть неположительным), IO::SEEK_CUR (отсчет от текущей позиции файла). Аналогичным образом можно решить задачу и на языке Julia. Решение будет более простым, так как в этом языке мы можем сразу считывать данные из двоичных файлов в числовые переменные (в данном случае необходимо использовать вещественный тип Float64). Функция seek в языке Julia позволяет указывать позицию только от начала файла, однако имеются также функции seekstart(f) и seekend(f), перемещающие файловый указатель на начало и конец файла, и функция skip(f, offset), перемещающая файловый указатель на offset байт относительно его текущей позиции. Есть в этом языке и функция position(f), которая возвращает текущую позицию файлового указателя. [Julia] function solve()
task("File25")
f = open(get(), "r+")
while !eof(f)
x = read(f, Float64)
skip(f, -8)
write(f, x^2)
end
close(f)
end
Теперь приведем второй вариант решения задачи, использующий вспомогательный файл. Для языка Ruby в этом варианте по-прежнему будут использоваться методы pack и unpack, однако файлы будут открываться либо только на чтение, либо только на запись, и поэтому не будет необходимости в прямом доступе к элементам файла. [Ruby] task "File25"
f = File.open get_s, "rb"
f1 = File.open "f25.tmp", "wb"
until f.eof? do
s = f.read 8
x = s.unpack "d"
f1.write([x[0]**2].pack "d")
end
f.close
f1.close
File.delete f.path
File.rename f1.path, f.path
В данной программе вспомогательный файл связывается с файловой переменной f1 и открывается только на запись, тогда как исходный файл открывается только на чтение. Элементы исходного файла последовательно считываются в переменную s, после чего они декодируются, возводятся в квадрат, кодируются и записываются во вспомогательный файл. В конце программы с помощью методов delete и rename класса File выполняется удаление исходного файла f (в качестве параметра функции указывается имя файла, которое остается доступным для переменной f даже после закрытия файла), а затем выполняется переименование вспомогательного файла f1. Приведем аналогичный вариант решения для языка Julia. Поскольку в этом языке по дескриптору файла нельзя определить его имя, а функции для удаления (rm) и переименования (mv), как и в языке Ruby, требуют указания имен файлов, в программе имена файлов предварительно сохраняются во вспомогательных переменных. [Julia] function solve()
task("File25")
s, s1 = get(), "f25.tmp"
f = open(s, "r")
f1 = open(s1, "w")
while !eof(f)
write(f1, read(f, Float64)^2)
end
close(f)
close(f1)
rm(s)
mv(s1, s)
end
Строковые и текстовые файлы: File67, Text21В данном пункте описываются особенности выполнения заданий на обработку строковых файлов (т. е. двоичных типизированных файлов, элементами которых являются строки), а также текстовых файлов, содержащих строки различной длины, оканчивающиеся маркерами конца строки. Двоичные строковые файлыВ качестве примера задания на строковые файлы рассмотрим задание File67. File67°. Дан строковый файл, содержащий даты в формате «день/месяц/год», причем под день и месяц отводится по две позиции, а под год — четыре (например, «16/04/2001»). Создать два файла целых чисел, первый из которых содержит значения дней, а второй — значения месяцев для дат из исходного строкового файла (в том же порядке). Двоичные строковые файлы отличаются от стандартных текстовых файлов тем, что в них не используются специальные маркеры конца строки, а все строки — файловые элементы — имеют одинаковый размер. Это позволяет использовать прямой доступ к любому файловому элементу, а также дает возможность изменять отдельные элементы-строки, не затрагивая их соседей. Размер строки может быть выбран произвольным образом; при выполнении заданий на языке Ruby с использованием задачника Programming Taskbook элементы строковых файлов имеют размер 80 символов. Таким образом, для чтения этих элементов надо использовать функцию read(80), а перед записью элементов в такой файл необходимо обеспечить их нужный размер (80 символов), дополняя их справа требуемым числом пробелов. Для обработки строковых файлов описанного выше формата нет необходимости выполнять дополнительную перекодировку двоичных данных. Однако в задании File67 требуется сформировать два двоичных файла с числовыми данными, для которых подобная перекодировка необходима. Поэтому в программе на языке Ruby потребуется использовать метод pack. Для выделения из строки фрагмента, изображающего целое число, надо использовать операцию среза для строки, к результату которой достаточно применить функцию to_i преобразования строки в целое число. Таким образом, решение задачи File67 примет следующий вид: [Ruby] def solve()
task "File67"
f = File.open get_s, "rb"
f1 = File.open get_s, "wb"
f2 = File.open get_s, "wb"
until f.eof? do
s = f.read 80
f1.write([s[0,2].to_i].pack "i")
f2.write([s[3,2].to_i].pack 'i')
end
f.close
f1.close
f2.close
end
Решение на языке Julia выглядит аналогичным образом. Приведем его текст, а затем прокомментируем его. [Julia] function solve()
task("File67")
f = open(get(), "r")
f1 = open(get(), "w")
f2 = open(get(), "w")
b = Vector{UInt8}(undef, 80)
while !eof(f)
readbytes!(f, b)
s = decode(b, "UTF-8")
write(f1, parse(Int32, s[1:2]))
write(f2, parse(Int32, s[4:5]))
end
close(f)
close(f1)
close(f2)
end
В данном случае приходится использовать функцию readbytes!, которая
выполняет те же действия, что и функция read для языка Ruby, а именно, читает из файла указанное количество
байт. Однако для использования этой функции необходимо заранее создать массив байт (то есть элементов типа UInt8)
требуемого размера и передать его в качестве второго параметра функции readbytes! (восклицательный знак в конце
ее имени указывает на то, что при ее выполнении происходит изменение некоторых ее параметров).
Кроме того, полученный массив байт необходимо преобразовать в строку. Для этого предназначена функция decode, вторым параметром которой надо указать требуемую кодировку символов. В нашем случае строка содержит только символы из таблицы ASCII, поэтому можно указать, например, кодировку "UTF-8". Однако если бы строка содержала русские буквы, то было бы необходимо указать кодировку "CP1251", так как задачник использует файлы именно в такой кодировке. Заметим, что эта функция определена в дополнительном модуле StringEncodings, который автоматически подключается к программе с решением, так как соответствующая директива имеется в файле PT.jl. Парной к функции decode является функция encode, которая преобразует текстовую строку (которая в языке Julia всегда имеет кодировку UTF-8) в набор байт, соответствующий кодировке, указанной вторым параметром функции encode. Эта функция может оказаться полезной при записи данных с двоичные строковые (а также текстовые) файлы. Наконец, после получения требуемой строки, мы извлекаем из нее подстроки, используя срезы s[1:2] и s[4:5] (в срезах указывается начальный и конечный индекс; напомним, что в языке Julia индексирование начинается от 1), и преобразуем их в числа типа Int32, используя функцию parse. Текстовые файлыВ качестве примера задания на текстовые файлы рассмотрим задание Text21. Text21°. Дан текстовый файл, содержащий более трех строк. Удалить из него последние три строки. Строки в текстовом файле имеют разную длину, и, таким образом, нельзя изменить одну из них, не «затрагивая» соседние. Поэтому преобразование текстовых файлов, как правило, выполняется с помощью вспомогательного текстового файла. Во вспомогательный файл записываются необходимые результирующие данные, после чего исходный файл удаляется с диска, а имя вспомогательного файла заменяется на имя исходного. Различная длина строк в текстовом файле также вынуждает организовывать их считывание последовательно, от первой до последней строки; при этом до завершения считывания файла невозможно определить количество содержащихся в нем строк. В языке Ruby для текстовых файлов при указании режима открытия не следует указывать символ b (признак двоичного файла). В программах на этом языке (а также на языке Julia) текстовые файлы обычно открываются в одном из трех режимов: "r" — чтение, "w" — запись, приводящая к полному обновлению содержимого файла, и "a" — режим дополнения (append), при котором новые данные добавляются в конец существующего файла. При этом для чтения отдельной текстовой строки должна использоваться функция readline, которая для языка Ruby возвращает не только содержимое строки, но и завершающий ее маркер в виде символа "\n", а для языка Julia может как возвращать, так и отбрасывать завершающий маркер (по умолчанию маркер отбрасывается). Для контроля того, достигнут или нет конец файла, можно, как обычно, использовать метод eof? в Ruby и функцию eof в Julia. Приведем решение задачи Text21, учитывающее отмеченные выше особенности текстовых файлов: [Ruby] def solve()
task "Text21"
f = File.open get_s, "r"
n = 0
until f.eof? do
f.readline
n += 1
end
f.close
f = File.open f.path, "r"
f1 = File.open "t21.tmp", "w"
(n-3).times do
f1.write f.readline
end
f.close
f1.close
File.delete f.path
File.rename f1.path, f.path
end
[Julia] function solve()
task("Text21")
s, s1 = get(), "t21.tmp"
f = open(s, "r")
n = 0
while !eof(f)
s2 = readline(f)
n += 1
end
close(f)
f = open(s, "r")
f1 = open(s1, "w")
for i in 1:n-3
write(f1, readline(f) * "\n")
end
close(f)
close(f1)
rm(s)
mv(s1, s)
end
Напомним, что операция сцепления строк в языке Julia обозначается символом *. Этот вариант решения является неэффективным, поскольку требует двух просмотров исходного файла f: первый — для определения его размера, который записывается в переменную n, второй — для создания вспомогательного файла f1, содержащего все строки исходного файла, кроме трех последних. Приведем еще один способ решения, который, хотя и требует единственного просмотра исходного файла, также является неэффективным, так как сохраняет в памяти всё содержимое файла: [Ruby] def solve()
task "Text21"
f = File.open get_s, "r"
s = f.readlines
f.close
f = File.open f.path, "w"
for e in s[0..-4] do
f.write(e)
end
f.close
end
[Julia] function solve()
task("Text21")
name = get()
f = open(name, "r")
s = readlines(f)
close(f)
f = open(name, "w")
for e in s[1:end-3]
write(f, e * "\n")
end
close(f)
end
В этой программе используется функция readlines, считывающая все строки файла и возвращающая их в виде
массива. Для получения всего массива s, за исключением последних трех элементов, проще всего воспользоваться
операцией среза. В программе на языке Ruby мы использовали срез со вторым отрицательным аргументом: Тем не менее, задание Text21 можно выполнить и за один просмотр исходного файла, причем не сохраняя в памяти все содержимое файла, если воспользоваться следующим наблюдением: строка должна быть записана во вспомогательный файл, если после нее в исходном файле находятся по крайней мере три строки. Таким образом, записывать очередную строку во вспомогательный файл следует только после считывания из исходного файла трех следующих за ней строк. Благодаря такому упреждающему считыванию необходимость в предварительном определении размера исходного файла отпадает. Для хранения строк, которые уже считаны из исходного файла, но еще не записаны во вспомогательный файл, удобно использовать список из трех элементов. Приведем программу, реализующую описанный выше эффективный однопроходный алгоритм решения задачи: [Ruby] def solve()
task "Text21"
f = File.open get_s, "r"
f1 = File.open "t21.tmp", "w"
a = []
3.times {a.push f.readline}
until f.eof?
f1.write a.shift
a.push f.readline
end
f.close
f1.close
File.delete f.path
File.rename f1.path, f.path
end
[Julia] function solve()
task("Text21")
s, s1 = get(), "t21.tmp"
f = open(s, "r")
f1 = open(s1, "w")
a = []
for i in 1:3
push!(a, readline(f))
end
while !eof(f)
write(f1, popfirst!(a) * "\n")
push!(a, readline(f))
end
close(f)
close(f1)
rm(s)
mv(s1, s)
end
Прокомментируем полученную программу. Вначале список a заполняется первыми тремя строками из исходного файла (по условию файл содержит не менее трех строк). На каждой итерации цикла while во вспомогательный файл записывается первая строка из списка а (в этот момент уже известно, что после данной строки в исходном файле содержатся, по крайней мере, три строки: две из этих строк уже хранятся в списке, а непустая третья строка является текущей строкой файла). Записанная строка немедленно удаляется из массива (это действие обеспечивается в языке Ruby методом shift, а в языке Julia — функцией popfirst!). Затем в конец списка добавляется очередная строка из исходного файла (это действие, как и добавление трех начальных строк, обеспечивается методом push для языка Ruby и функцией push! для языка Julia). После завершения цикла while во вспомогательный файл будут записаны все строки исходного файла, кроме последних трех, а эти три последние строки будут содержаться в списке a. Примечание. Несмотря на то что приведенные программы правильно решают поставленную задачу, они имеют один недостаток, который проявляется, если обрабатываемый файл содержит текст на русском языке. Этот недостаток обусловлен тем, что исходный файл имеет однобайтную кодировку Windows-1251, тогда как по умолчанию в языках Ruby и Julia предполагается, что содержимое обрабатываемых файлов имеет кодировку UTF-8. Поэтому при считывании данных из файлов в другой кодировке мы получим строки с неверным, с точки зрения программы, содержимым (хотя при их записи в другой файл с той же кодировкой ничего плохого не произойдет, что мы и увидели при выполнении задания). Проблемы возникнут, если мы захотим обработать прочитанные строки в самой программе. Например, если просто попытаться вывести строку с русским текстом, прочитанную из файла с кодировкой Windows-1251, в раздел отладки (используя функцию show), то и в программе на языке Ruby, и в программе на языке Julia мы получим текст из вопросительных знаков, означающий, что данную строку нельзя интерпретировать как строку в кодировке UTF-8. Для решения отмеченной проблемы в языке Ruby достаточно указать правильную кодировку при открытии файла; это делается путем добавления названия кодировки к строке, определяющей режим доступа, например, "r:CP1251" или "w:UTF-8" (хотя кодировку UTF-8 указывать не обязательно, так как она используется по умолчанию). В результате при считывании строки из файла (или ее записи в файл) будет автоматически выполняться ее перекодировка, благодаря чему строка, полученная в программе, всегда будет иметь кодировку UTF-8. В языке Julia, к сожалению, отсутствуют столь же простые средства для работы с файлами
в различных кодировках. Однако требуемую перекодировку можно выполнить уже после считывания строки из файла
(или непосредственно перед записью строки в файл), используя уже упоминавшиеся ранее функции decode и encode
из модуля StringEncodings. Например, для получения из файла f1 с однобайтной кодировкой cp1251
очередной строки и ее немедленного преобразования в строку s2, имеющую кодировку UTF-8,
достаточно выполнить оператор
|
|
|
Разработка сайта: |
Последнее обновление: |