|
Programming Taskbook |
|
|
||
|
Электронный задачник по программированию |
||||
|
© М. Э. Абрамян (Южный федеральный университет, Университет МГУ-ППИ в Шэньчжэне), 1998–2026 |


|
|
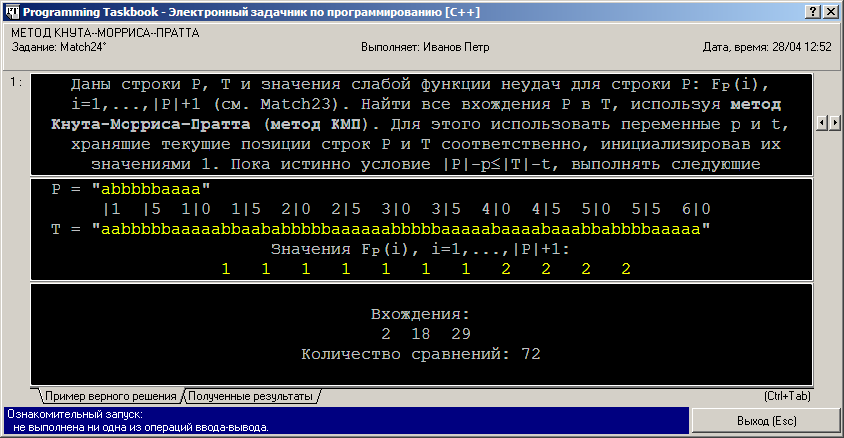
Поиск методом Кнута–Морриса–Пратта: Match24 (язык C++)Следующий пример посвящен реализации основного алгоритма метода Кнута–Морриса–Пратта (метода КМП) в предположении, что препроцессинг для этого метода уже выполнен. Match24°. Даны строки P, T и значения слабой функции неудач для строки P: FP(i), i = 1, …, |P| + 1 (см. Match23). Найти все вхождения P в T, используя метод Кнута–Морриса–Пратта (метод КМП). Для этого использовать переменные p и t, хранящие текущие позиции строк P и T соответственно, инициализировав их значениями 1. Пока истинно условие |P| − p ≤ |T| − t, выполнять следующие действия: • пока p ≤ |P| и P[p] = T[t], увеличивать на 1 переменные p и t; Вывести начальные позиции всех найденных вхождений P в T (в порядке возрастания), а также количество сравнений символов, потребовавшееся при выполнении алгоритма. Примечание. Ускорение в методе КМП (по сравнению с наивным алгоритмом поиска) достигается за счет того, что изменение значения p (интерпретируемое как сдвиг образца P вправо относительно текста T) может выполняться на величину, большую 1. А именно, если несовпадение символов обнаружилось для P[i + 1] и T[t], то строка P сразу сдвигается вправо на i − spi(P) позиций (так что совмещаются символы P[spi(P) + 1] и T[t]). При этом гарантируется, что spi(P) начальных позиций в P совпадут с соответствующими позициями строки T, поэтому очередная проверка выполняется для символов P[spi(P) + 1] и T[t]. Описанный в данном задании алгоритм поиска используется в дальнейшем, с соответствующими модификациями, и в других классических алгоритмах: модифицированном методе КМП (см. Match25), методе реального времени (Match36), методах, основанных на правиле плохого символа (Match41–42) и правиле хорошего суффикса (Match46–47), а также в методе Бойера-Мура (Match53–56), объединяющем эти правила. Будем выполнять задание на языке C++. В версии 4.10 задачника в качестве программной среды для языка C++ можно использовать Microsoft Visual C++ 6.0 и Microsoft Visual Studio .NET 2003, 2005, 2008 и 2010. Выбрать одну из доступных сред языка C++ можно из контекстного меню программного модуля PT4Load, описанного в предыдущем примере. Будем предполагать, что выбрана среда Microsoft Visual Studio .NET 2010 для языка C++; в этом случае в заголовке окна модуля PT4Load будет указан текст «[VCNET4]». В других средах C++ действия при выполнении задания будут аналогичными. Созданный для задания Match24 проект-заготовка на языке C++ состоит из нескольких файлов, однако в редактор среды будет загружен один файл с именем Match24.cpp. Именно в этом файле надо запрограммировать решение задачи. Приведем содержимое данного файла: #include "pt4.h"
using namespace std;
void Solve()
{
Task("Match24");
}
Файл содержит директиву подключения заголовочного файла pt4.h с объявлениями вспомогательных функций задачника и описание функции Solve, которая будет содержать текст решения (разумеется, в решении могут использоваться и вспомогательные функции, описанные в том же файле или в других файлах, включенных в проект). Первым оператором функции Solve является оператор вызова функции Task, инициализирующей задание Match24. Как обычно, созданный проект-заготовка доступен для немедленного запуска; для этого достаточно нажать клавишу [F5]. В результате на экране появится окно задачника:
В разделе исходных данных приводятся две строки — образец P и текст T, в котором осуществляется поиск, а также набор значений слабой функции неудач, которая должна вычисляться в ходе препроцессинга метода КМП. В данном задании выполнять препроцессинг не требуется (этому этапу метода КМП посвящена специальная серия заданий, одно из которых будет рассмотрено в следующем примере). При выполнении заданий на языке C++ необходимо учитывать, что индексация символов строк и элементов массивов в данном языке начинается с 0, поэтому в реализацию описанных в заданиях алгоритмов необходимо вносить соответствующие корректировки. С учетом этих корректировок программа, решающая задачу, примет следующий вид: #include "pt4.h"
using namespace std;
void Solve()
{
Task("Match24");
string P, T;
pt >> P >> T;
int n = P.length(), m = T.length(), *F = new int[n+1];
for (int i = 0; i < n+1; i++)
pt >> F[i];
int p = 1, t = 1, cnt = 0;
while (n-p <= m-t)
{
while (p <= n && P[p-1] == T[t-1])
{
p++;
t++;
cnt++;
}
if (p == n+1)
pt << t-n;
else
cnt++;
if (p == 1)
t++;
p = F[p-1];
}
pt << cnt;
}
В первой части программы выполняется ввод исходных данных. Для этого в программе на языке C++ можно использовать специальный поток ввода-вывода pt, объявленный в заголовочном файле pt4.h. Для хранения строковых данных используется тип string, для которого, в отличие от типа char*, не требуется явно выделять память операцией new. Значения функции неудач заносятся в массив F; при этом элемент массива F[0] соответствует значению функции FP(1), элемент F[1] - значению FP(2) и т. д. Для хранения текущих позиций строк P и T используются переменные p и t соответственно; длины строк P и T сохраняются во вспомогательных переменных n и m. Алгоритм поиска подстрок по методу КМП программируется в соответствии с его описанием, приведенным в формулировке задания; следует лишь вносить необходимые поправки (равные –1) при обращении к символам строк и элементам массива F. Позиции найденных вхождений немедленно выводятся с использованием того же потока pt. Необходимо также выполнять корректный подсчет числа сравнений символов. Для хранения этого числа используется переменная cnt, которая увеличивается на каждой итерации цикла, а также при выходе из него в случае, если выход произошел из-за обнаружения несовпадения символов строк P и T (ср. с аналогичной ситуацией во втором варианте решения задачи Match4). При запуске этого варианта решения на информационной панели окна задачника будет выведено сообщение «Верное решение. Тест номер 1 (из 5)», а после пяти подобных запусков — сообщение «Задание выполнено!». Правильность найденных вхождений можно проверить непосредственно, сравнивая соответствующие фрагменты строки T со строкой P; при этом удобно пользоваться линейкой, отображаемой между строками. При выполнении данного задания можно дополнительно исследовать вопрос о том, насколько ускоряется поиск вхождений при использовании метода КМП по сравнению с наивным алгоритмом поиска. Во многих заданиях соответствующие сведения приводятся самим задачником. В данном задании дополнительная информация не выводится, поскольку в реализованном варианте метода КПМ не выполнялся препроцессинг строки P (в ходе которого определяются значения функции неудач), поэтому найденное число сравнений является лишь частью общего количества сравнений, требуемых в методе КМП. Однако мы все же добавим в программу фрагмент, выполняющий поиск с помощью наивного алгоритма. Это позволит, в частности, познакомиться с дополнительными отладочными возможностями задачника. Мы уже реализовали фрагмент наивного алгоритма, проверяющий наличие вхождения, начинающегося с позиции k (см. пример решения задачи Match4). Осталось выполнить этот фрагмент в цикле и учесть особенности индексации символов в строках C++. При обнаружении очередного вхождения будем выводить его начальную позицию (отсчитываемую от 1); после завершения поиска выведем потребовавшееся число сравнений символов. Будем использовать более наглядный вариант наивного алгоритма, использующий цикл с параметром и директиву break явного выхода из цикла. Следующий фрагмент надо добавить в конец функции Solve: cnt = 0;
for (int k = 0; k <= m-n; k++)
{
int res = k;
for (int i=0; i < n; i++)
{
cnt++;
if (P[i] != T[k+i])
{
res = -1;
break;
}
}
if (res >= 0)
Show(res+1, 4);
}
ShowLine();
Show("Количество сравнений: ", cnt);
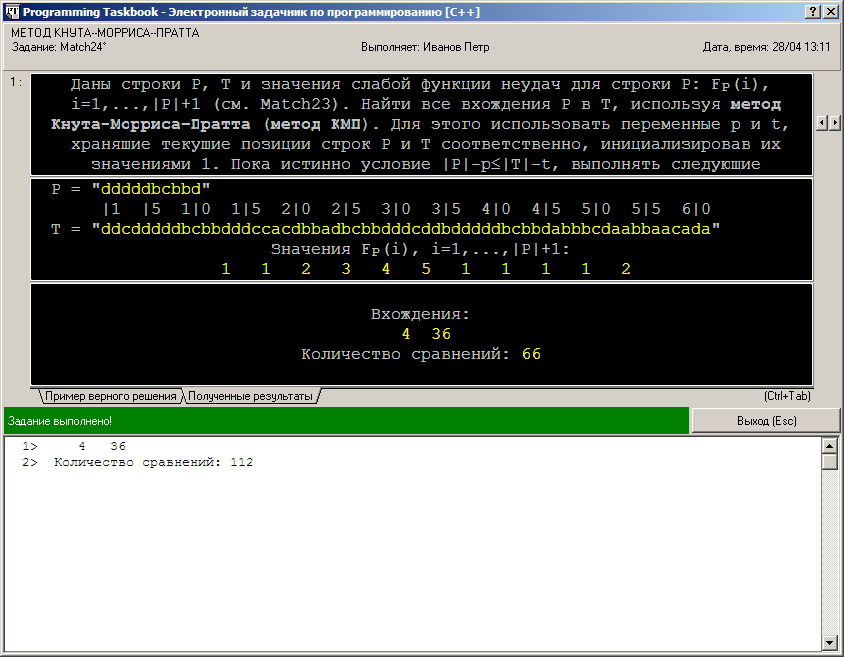
Следует обратить внимание на то, что вывод результатов в данном фрагменте выполняется не с помощью потока ввода-вывода pt, а с использованием функций Show и ShowLine. Применение потока pt приведет в данном случае к сообщению об ошибке «Попытка вывести лишние результирующие данные», поскольку все данные, передаваемые задачнику с помощью потока pt, интерпретируются им как элементы результирующих данных. Если в процессе выполнения задания требуется просто вывести некоторые данные на экран (например, для отладки или, как в нашем случае, для дополнительного исследования алгоритма), то для этого необходимо использовать специальные отладочные функции задачника Show и ShowLine. Эти функции позволяют вывести данные в специальный раздел отладки окна задачника, который отображается на экране только в случае, если в него выведен хотя бы один элемент данных. Выводимые данные можно форматировать и снабжать комментариями. В нашем случае для вывода начальной позиции каждого найденного вхождения выделяются 4 экранные позиции (благодаря указанию последнего, необязательного параметра 4 в функции Show), а выведенное число сравнений символов снабжается комментарием «Количество сравнений» (благодаря указанию дополнительного первого параметра функции Show). Функция ShowLine обеспечивает переход на новую экранную строку после вывода указанного в ней элемента данных; она может вызываться без параметров. После запуска дополненной программы на экране появится окно задачника с разделом отладки:
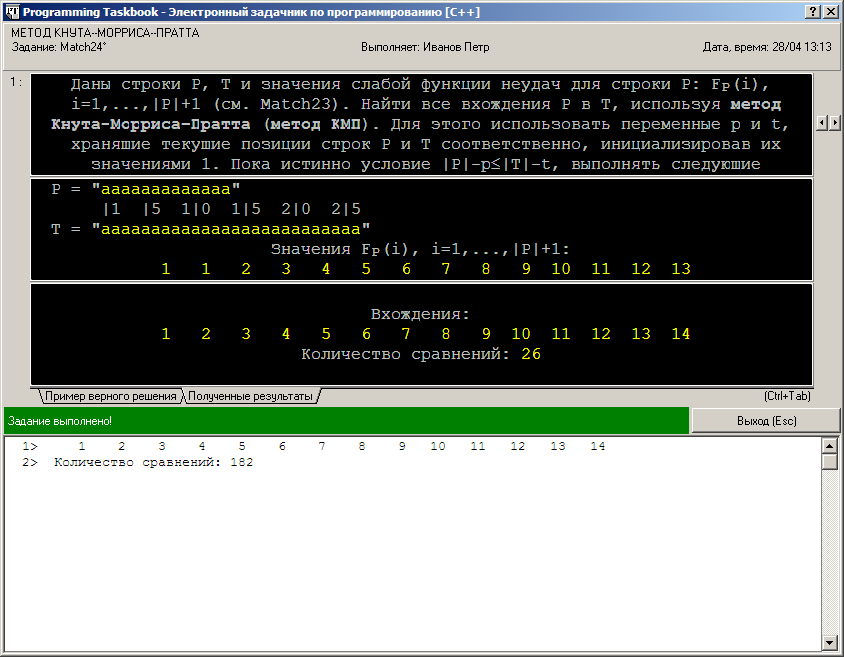
Раздел отладки располагается в нижней части окна и содержит данные, выведенные с помощью функций Show и ShowLine. Подчеркнем, что наличие этих данных никак не скажется на проверке правильности решения. Информация в разделе отладки показывает, что, во-первых, оба реализованных метода поиска обнаружили одни и те же вхождения образца P в строке T, и, во-вторых, что в наивном алгоритме для выполнения поиска потребовалось существенно больше сравнений символов. Особенно впечатляющим будет различие в числе сравнений в случае, когда строки содержат большое число повторяющихся символов:
Отладочные возможности задачника, использованные в добавленном фрагменте, доступны при выполнении заданий и на других языках программирования (см. следующий пример).
|
|
|
Разработка сайта: |
Последнее обновление: |